
[物件偵測] S1: R-CNN 簡介
前言
R-CNN可以說是CNN有效應用於物件辨識領域中的一個重要里程碑。它應用region proposal的方法來將這些提案的區域送入CNN抽取特徵,以及後頭的分類、檢測網路中。 在經典的物件辨識競賽PASCAL VOC的2010~2012年之間,競賽的成果發展趨緩。已往利用SIFT、HOG這類的影像識別方法僅僅符合生物初級的視覺機制,然而對於一個物體的識別與追蹤,是存在於更深層的神經傳導機制下的。自從CNN崛起以後,這篇研究的動機就是要接起deep learning和object detection之間的橋樑,且證實可以在辨識大賽中獲得前所未有的突破。研究目標可以分為兩項:
- 與deep network搭配來對物體定位
- 利用少量有標記之資料即可訓練的高彈性模型
論文:
Rich feature hierarchies for accurate object detection and semantic segmentation
Region Proposal
第一次接觸物件辨識的人,肯定對這個詞很陌生,而且這個詞會一路出現在後面Two-stages的物件辨識模型中,所以先確定知道什麼是region proposal是很重要的。
假設在一張有狗的圖像中,我們要找出這隻狗在哪裡。有一個很直觀的方法,就是訂定一個固定的尺寸框,然後逐一像素的移動這個框(或可稱sliding-window,如圖中橘框),去看這個框框到的影像是狗的機率最高,作為「狗在哪裡」的評估依據。但是可想而知,在整張圖像上做sliding-window是非常費時費力的一件事情。
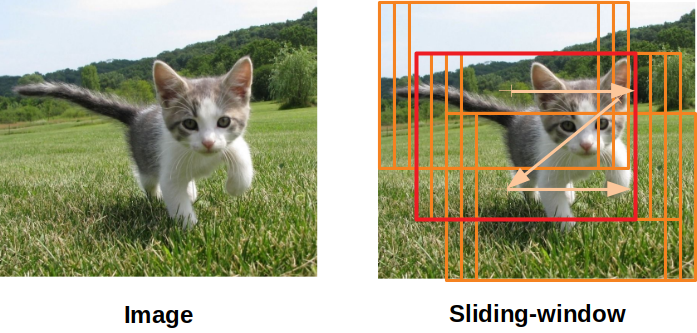
而是有個比較好的想法是,先在圖像上找到「比較有可能是狗的區域」(如圖中橘色框),再來將這些區域做評估。我們就稱這些被提出來的區域,叫做”Region Proposals”。
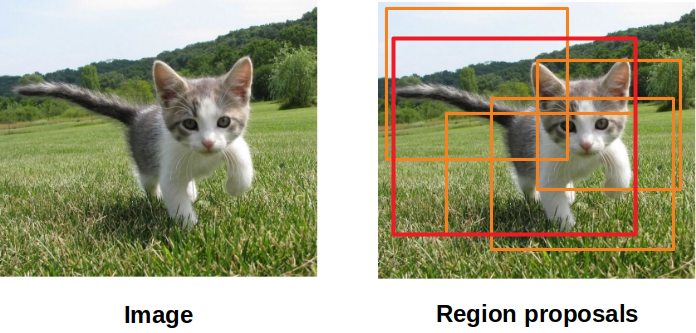
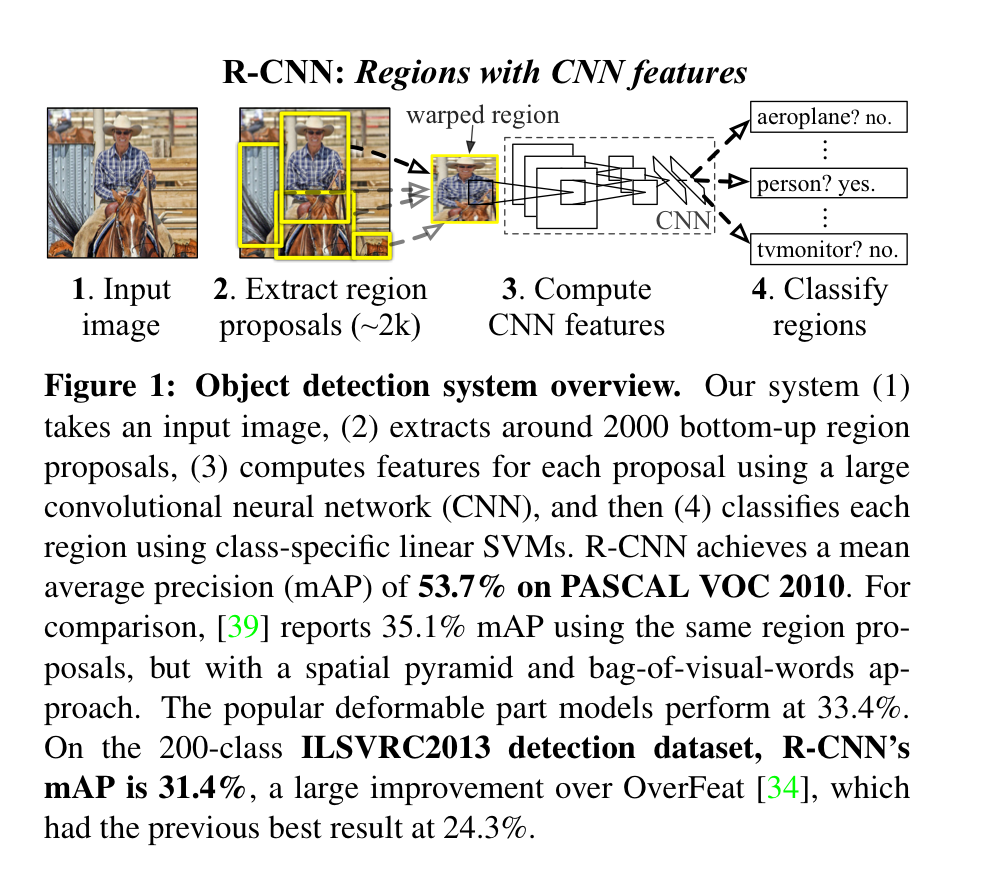
演算法架構
下圖是論文中所給出的演算架構。簡單來說,R-CNN的概略步驟為:
- 在輸入圖片上,以selective search先取出約2千個region proposals
- 將這些region利用CNN計算出他們的feature vector
- 將其各自的feature vector再丟入category-specific linear SVM中去分類
- 同時將Proposals送進BBox Regressor中迴歸與ground truth的差異量
Region Proposals - Selective search
Selective Search 講起來又可以寫一篇,不過這邊還是簡單提一下他在幹麻。簡單說,這套演算法會先計算影像中所有臨域之間的相似性,然後把相似性高的區域給合併起來,再繼續計算區域和區域之間的相似性,視需要看在什麼階段停止合併。在R-CNN中,會提出2000個proposals來進入後續計算。

Feature Extractor (Backbone Network)
R-CNN的backbone是AlexNet,並且以扣掉平均的227*227的RGB影像作為輸入,將最後獲得的4096維的feature vector送入後面的detector中。 而R-CNN的其中一個重點就在,他是使用已經在ImageNet上pre-trained的AlexNet,在轉移到domain的應用上。他們發現,因為ImageNet不管是影像、類別的數量都很豐富,所以在上面pre-train的model,基本上已經可以對大部分的自然物體做出很好的特徵提取,所以在轉移到domain的應用上時,其實不用再重新訓練backbone network,而是去訓練後面的detector就可以讓通常很少量的domain影像依然可以獲得很好的結果。 而在selective search 給出proposals後,在這裡會先設定一個IoU的閥值(0.5),來將每次的mini-batch的128筆資料中,將proposals區分成32 positive、96 negative兩種類型。
Class Detector - SVM
在分類的處理上,並不是使用像一般CNN後面的softmax分類層。這在論文的附錄當中有提到為什麼當時不直接簡單使用softmax就好。 當2000個proposals從backbone中提取出2000個feature vector出來(shape=2000×4096),就是要接著送入後面的SVM中。而作者利用N個SVM模型來分別計算各個vector屬於哪個類別的機率(shape=4096×N_class)
BBox Detector-Regressor
在bounding box的預測上,將它視為是regression的問題是很有效的。我們可以直接對model預測出來的bbox和ground-truth box之間的差異量進行回歸。假設Proposal的bbox P=(Px, Py, Pw, Ph),而ground-truth G=(Gx, Gy, Gw, Gh),則他們之間可以透過下式轉換:
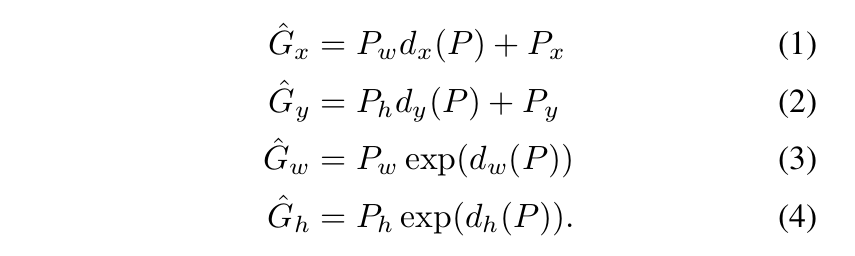
其中,d(P)項是線性函數,是P在pool-5層上的特徵 \(\phi_5(p)\) 的線性函數,如此這樣的式子也就將圖像信息考量進去。所以我們可以把d(P)寫成:
\[d_{★}(P)=\textbf{w}_{★}^{T}\phi_5(P)\]
其中,w就是待學習的參數,作者以ridge-regression的方式來進行最佳化。
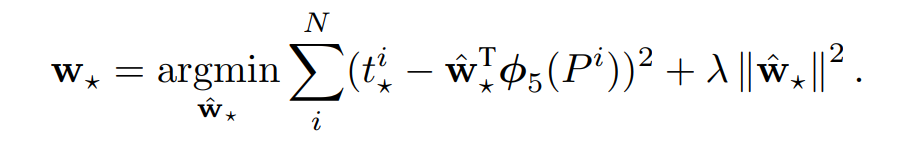
而其中的t如同下式表示:
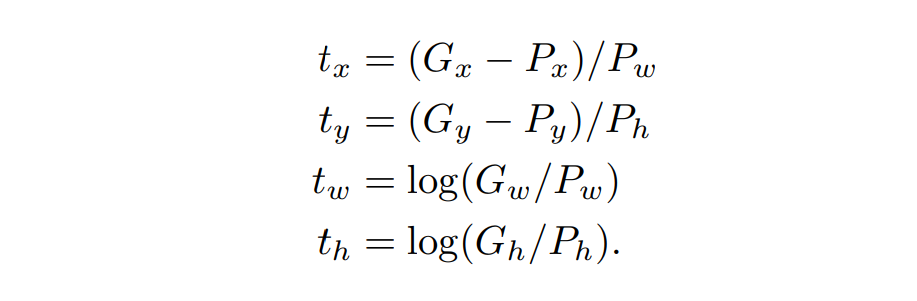
也就是P在x, y, w, h四個分量上與G的差異量。用這樣子來表示P和G之間的關係,也就可以使用最小二乘方法予以近似解。因此使用t作為optimize的目標式,可以很有效率的去對這部份做最佳化。
Detection
在detection的部份,流程和前面一樣,只不過最後面的處理bbox時,要導入NMS(Non-maximum suppression),來濾掉多餘的bbox,留下最好的。
總結
R-CNN可以分作3個階段看
- Region Proposals (selective search)
- Feature Extractor (AlexNet)
- Detector (SVM classifier, bbox regressor)
但是R-CNN分成這多階段的training,非常沒有效率,而且在training的時候,還要先把所有region proposals的feature vector都存到硬碟上,非常佔用硬體資源,也耗時許多。所以導致他的detection 表現只有47s/image的速度。也因此,後面出現了Fast R-CNN。
這是我個人對這篇論文的消化,如果有錯誤之處,請各位朋友指教或幫我指出
如果喜歡這篇文章,記得在下面幫我按個Recommend↓
謝謝~
留言