
[物件偵測] S3: Faster R-CNN 簡介
前言
前一篇我們提到了Fast R-CNN的改進,包括了減少冗贅的特徵提取動作,將ROI映射到feature maps上,並用ROI pooling 統一維度等等。但是為了迎來更快的偵測速度,在Proposals上的處理也需要納入整個模式的NN之中,一起用convolution來解決。
於是Faster R-CNN就此成型,它運用Region Proposals Network (RPN)搭配anchor box的設計,如同它論文的標題一樣 “Towards Real-Time Object Detection”,偵測速度來到了0.2s/image(相當於fps=5)的速度,雖然還不足以稱為real time,但是確實往這條路邁進了一大步。
論文:
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
演算法架構
首先來看論文裡面的一張圖:
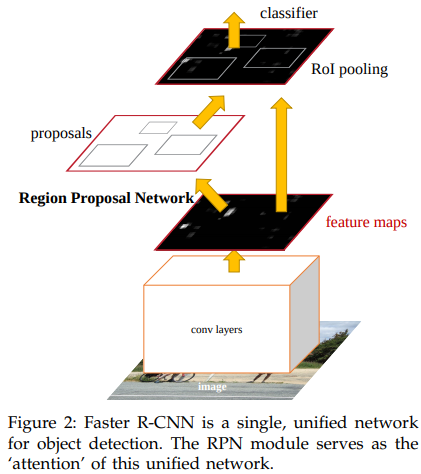
這張圖雖然簡單,但是點出了一個大重點就是在Region Proposal Network,後續我們會簡稱為RPN。RPN等於是在原本的Fast R-CNN的中間,多了一個分支來處理region proposals的小網路。所以今天這篇的重點就是來介紹Faster R-CNN加了anchor和RPN之後是如何運作的。
Anchor
在講RPN之前,要先來講講什麼是anchor。我們先知道RPN是一個要提出proposals的小model,而這個小model需要我們先訂出不同尺度、比例的proposal的邊界匡的雛形。而這些雛形就叫做anchor。
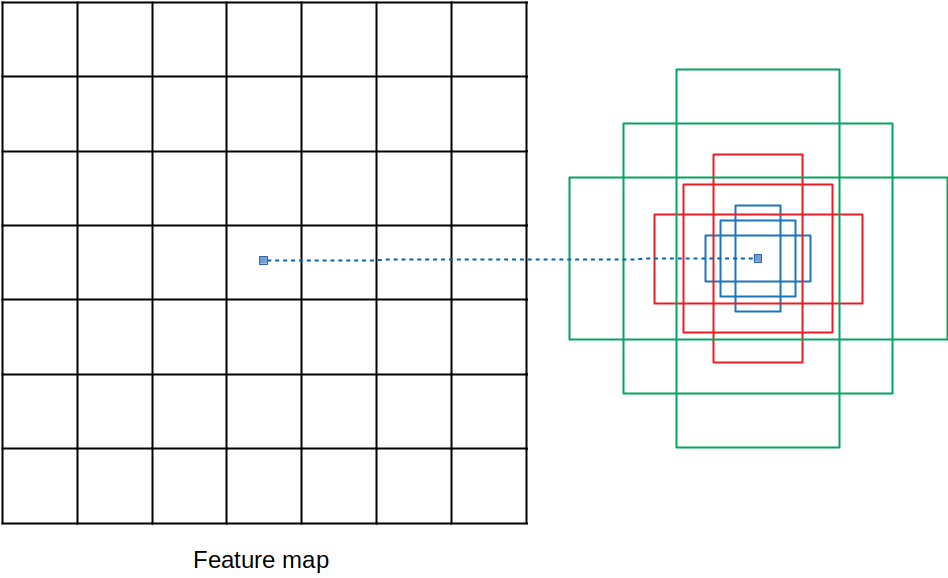
在論文裡面有提出不同尺度和比例組合的anchor對表現的影響,而論文之中最後採取的是3種尺度配上3種比例,得到k個anchor,也就是k=3×3=9。例如上圖,三種顏色代表3種尺度,各配上三種長寬比,而得到9種anchor。
假設今天的backbone network 是VGG16,則輸出的feature map維度就是7×7×512。當RPN在這個feature map上運作時,會在7×7的格子上都佈上這9個anchor。因此,在一個Feature map上初步產生的anchor就有7×7×9=441個,之後再進行後面的運算。
Region Proposal Network (RPN)
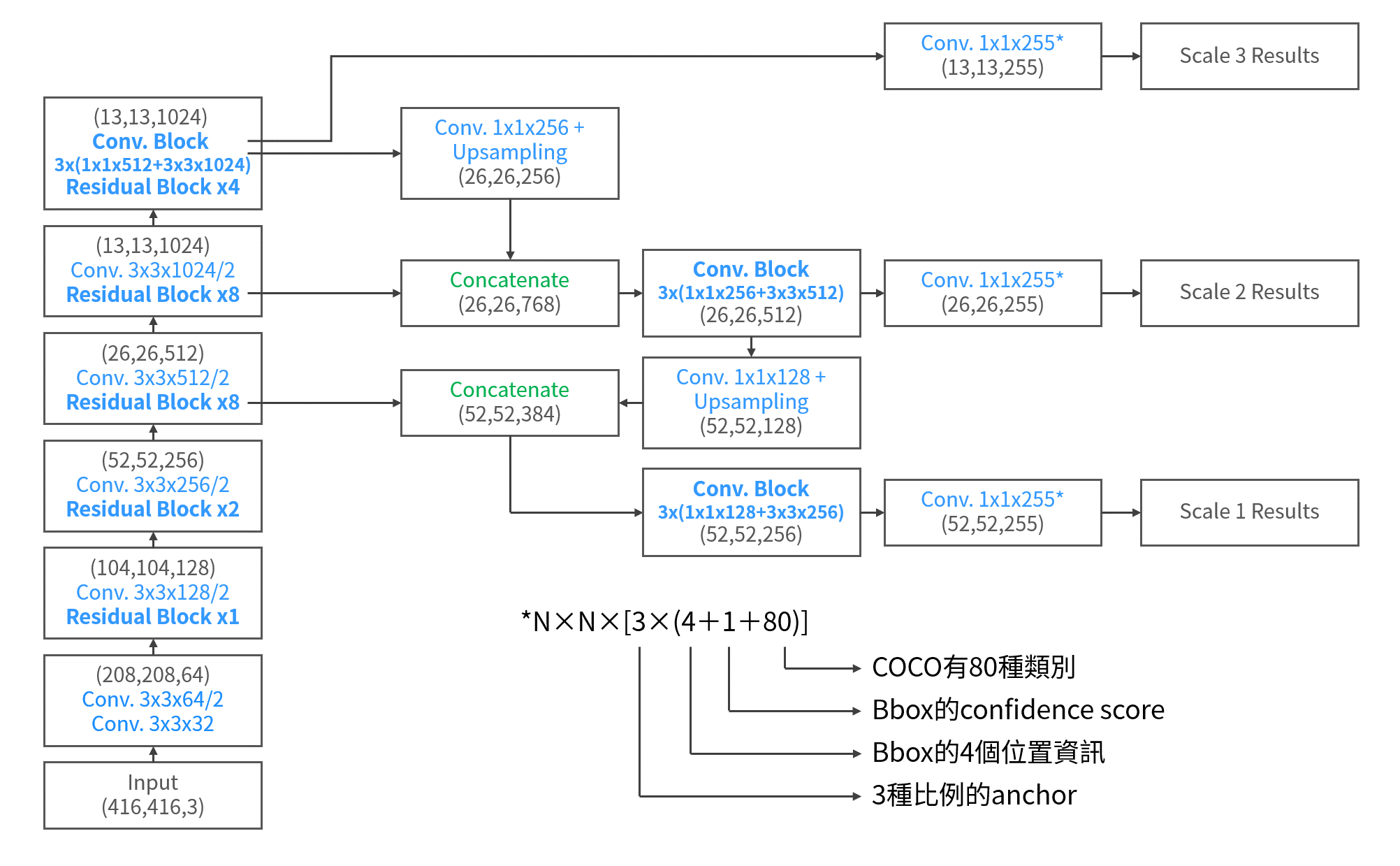
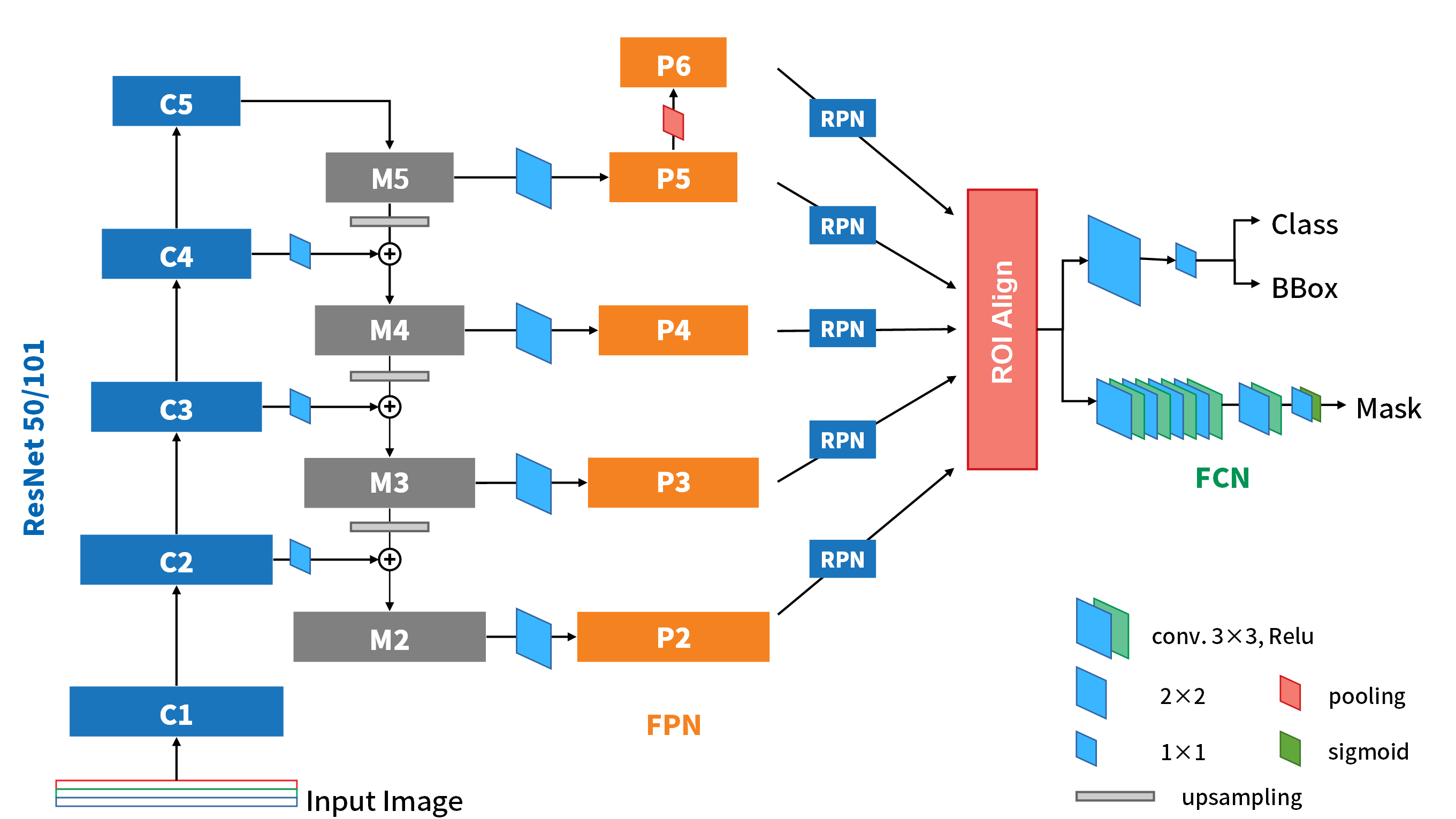
介紹完了anchor的機制之後,接著就是要講解RPN的細節了。下面這張圖是消化了很多文章、code、也參考了別人畫的架構圖後,自己重製的整個Faster R-CNN包含了詳細RPN的全架構圖。
前面Backbone的部份一樣承VGG16的例子,輸出了7×7×256的Feature map。RPN就是接在它和ROI pooling之間的小全捲積網路。當Feature maps 出來,進入到RPN之中,會先通過一次 3×3的conv.,之後分成上下兩路進行anchor的工作。
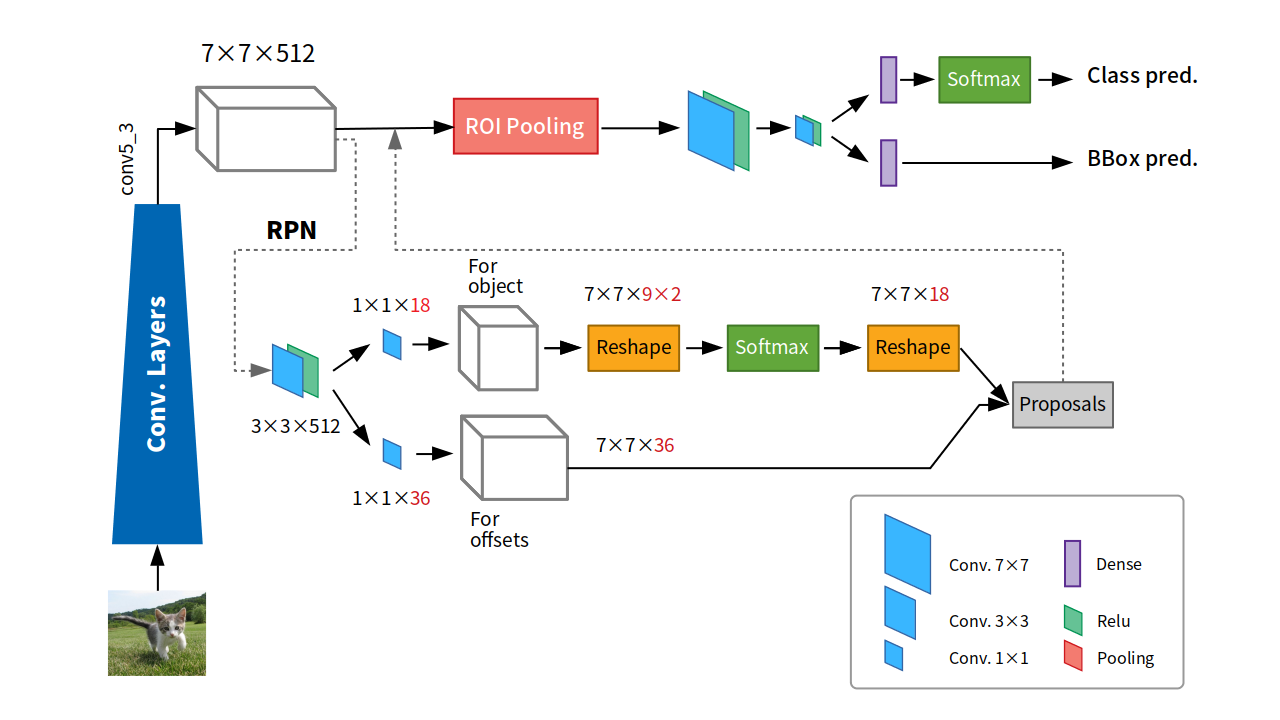
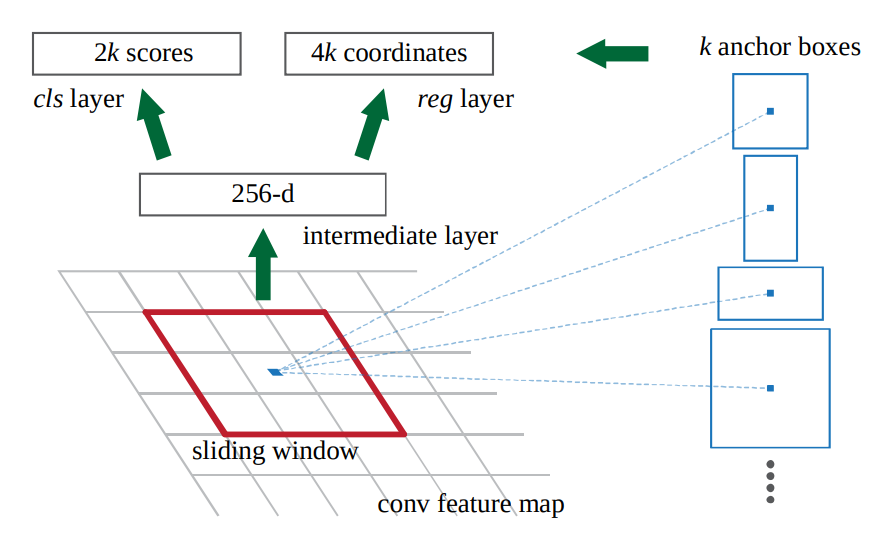
上路是負責判斷anchor之中有無包含物體的機率,因此,1×1的卷積深度就是9種anchor,乘上有無2種情況,得18。而下路則是負責判斷anchor的x, y, w, h與ground truth的偏差量(offsets),因此9種anchor,乘上4個偏差量(dx, dy, dw, dh),得卷積深度為36。下圖是論文對於這部份所提供的圖說。
在上路中,為了要判斷機率,所以需要預測這9個anchor的有無2種狀況,因此通過一次reshape,經過softmax獲得機率,最後再reshape回來。所以整個RPN走到這裡就已經接近尾聲,剩下就是要如何把好的anchor形成proposals交出去。那要如何評估出好的anchor呢?
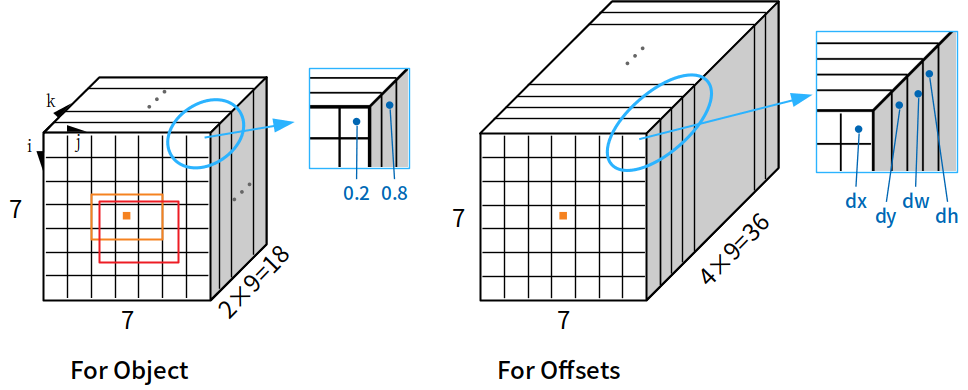
我們以上圖來說明。這是把上下兩路在最後提出proposals的步驟前,抓出來看的細部圖。我們以i, j, k分別代表三個軸的index,其中k是以每一組anchor為單位的,也就k=1~9。那麼,當softmax出來獲得每個位置的每一種anchor A(i,j,k)有無物體的機率後,RPN會先依照有物體的機率高低,將各個anchor排序。在論文當中,它只取前300高的anchor box來進入後面的程序,就足以獲得很好的結果,也同時節省運算時間。(如圖中橘框)
有了這前300個anchor (如圖中橘框),我們就可以到For offsets上,去找他們所對應的offsets量,帶回來修正anchor本身,成為最終的要提出來的300個proposals(如圖中紅框)。後續的工作,就和Fast R-CNN一樣了。
RPN Loss Function
為了訓練RPN,作者也提出一套供RPN訓練的損失函數:
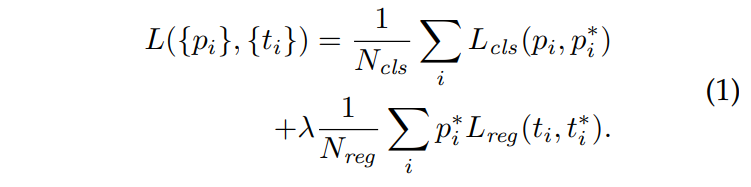
首先要定義positive、negative sample。有兩種情況的anchor box可以作為positive:
- 與ground truth有最大IoU的。
- 與任一ground truth的IoU大於0.7。
而negative的情況則是IoU低於0.3的這些anchor。
Anchor會被RPN中的上路,以「有無物體」的分類器評估機率,所以這裡的目標就是有物體(\(p^{* }\)=1)、沒物體(\(p^{* }\)=0)來計算\(L_{cls}\)。而下路的部分則是計算offsets ,只有positive sample會對這裡的\(L_{reg}\)貢獻!
結論
透過上面所說的這些設計,Faster R-CNN把原先獨立處理proposals的部分也整合進了網路架構中,且也用全卷積網路處理,搭配不同尺度和比例的anchor予以proposals的預測。這整個流程的整併,讓Faster R-CNN的速度也出現明顯的提昇,且mAP的表現並沒有降低,反而讓表現又提升了。
當然,雖然Faster R-CNN算是在two-stage的物件偵測模型出人頭地,但是一樣有著不夠好的地方:
- 雖然有9種anchor的雛形可供RPN使用,但是只在單一個解析度的feature map上進行提取,對於影像中不同大小的物體解析力不夠全面。
- 網路架構越來越大,對於計算設備和記憶體的需求也越來越高。除了限制了應用層面的硬體要求以外,偵測速度5fps距離real time的願景還有些差距要克服。
- 整體架構的複雜度比one-stage 的模型複雜許多,較難理解,且運行速度也差很多。
R-CNN系列的分享到這裡先告一個段落,後面我會開始介紹one-stage 上的發展。
這是我個人對這篇論文的消化,如果有錯誤之處,請各位朋友指教或幫我指出
如果喜歡這篇文章,記得在下面幫我按個Recommend↓
謝謝~
留言