
[物件偵測] S4: YOLO v1 簡介
前言
在前面我們曾提過物件辨識現在有one-stage和two-stage兩大類的方法。之前介紹過的R-CNN系列都是屬於two-stage的方法,因為他們都需要先得到region proposal才能對物體進行定位,進而辨別。然而這樣的方法總歸因為多了一層處理proposals的結構,雖然辨識效果很好,但是往往速度就是快不起來,而且方法在理解上也不是那麼直覺。
而one-stage的網路,例如我們今天要介紹的YOLO,它對物體的定位和分類是一條龍完成的,影像的輸入通過網路之後,就可以直接輸出對應的物體位置和類別,非常直覺,也因此速度可以比two-stage快上很多。
論文:
You Only Look Once: Unified, Real-Time Object Detection
演算法架構
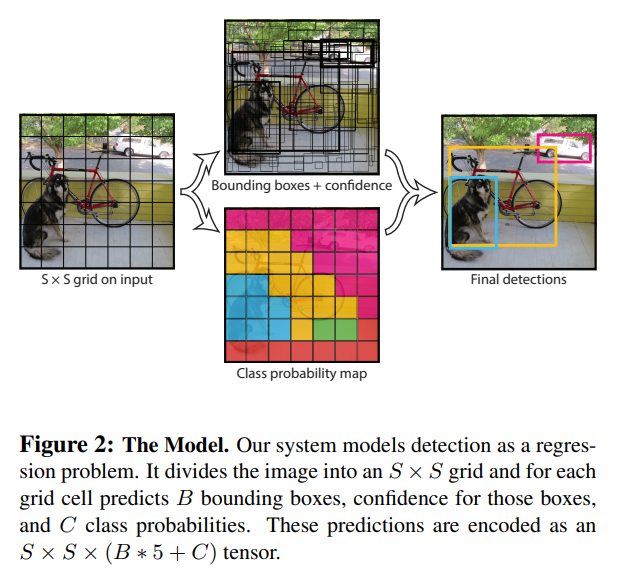
YOLO提出將物件辨識視為回歸問題的網路結構,所以整個網路執行到最後便直接給出邊界框(bounding box, bbox)的位置以及其最可能類別的confidence。就如同論文前面所提供的運算方式示意圖(下圖)。下面,就讓我們逐一剖析每個階段的設計是如何吧!
網路架構
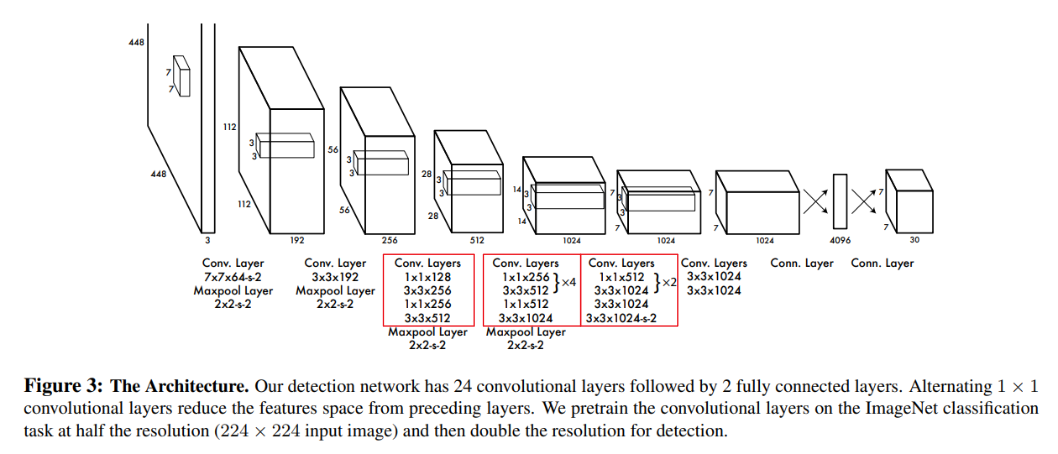
YOLOv1的網路架構如上圖所示。在輸入的圖像維度部分,YOLO的設定是448×448像素。而主架構的部分作者說這是參考當時Inception的設計方式構建出許多模組的堆疊搭配1×1的卷積搭配的網路結構(如上圖中的紅框所示)。
YOLO v1有趣的是輸出的設計,可以分成4個部分看,也就是最上面圖的圖說裡的S、B、C,還有5:
- S:假設你的卷積層最後的輸出維度是7×7,也就等於是在輸入的影像上切分了7×7的網格,這個S就是代表切成幾乘幾的網格。在這裏S=7。
- B:代表了每個格子裡面有幾個邊界框(Bounding box),在本篇論文中,B=2,也就是每個格子裡有兩種邊界框可供選擇。
- 5:這個5是由1個邊界框的數值(x, y, w, h),還有它含有物體的置信度(confidence)所構成。
- C:代表這個格子裡的兩個邊界框的類別的機率,如果是有20種類別(如PASCAL VOC),那麼C就是20。這裏特別的是,並不是每個邊界框都有一條類別陣列,而是一個網格配一天類別機率陣列,該網格中的邊界框都共用這個機率陣列。
所以由這4個部件所構成的輸出資料,維度就是S×S×(B×5+C),也就是7×7×(2×5+20)=7×7×30。更具體一點,如果我們把最後的7×7×30輸出層拿出來看,再拉出其中的一個格子會像下面這張圖:
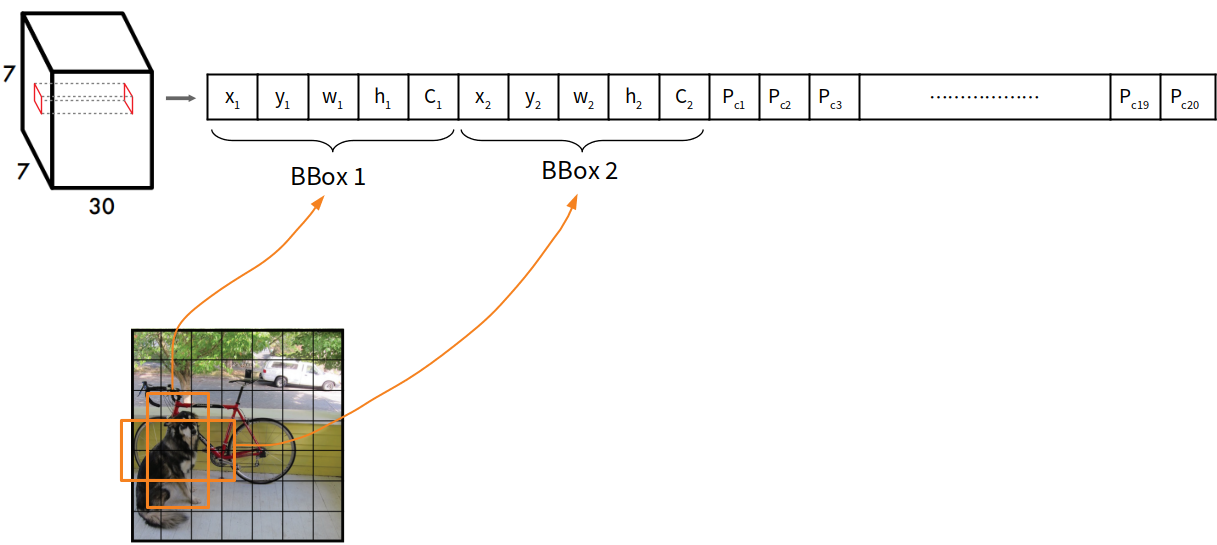
就如同我們上面所說的一樣,深度30是由5×2+20而來的。其中邊界框的四個位置數值是正規化的數值:
x = bbox的x位置 / 原影像寬度
y = bbox的y位置/ 原影像高度
w = bbox的高度 / 原影像寬度
h = bbox的高度 / 原影像高度
所以一張影像進來總共有7×7×2=98個bbox。
在活化函數的部份,整個網路除了輸出層,全都採用Leaky ReLU。
Training
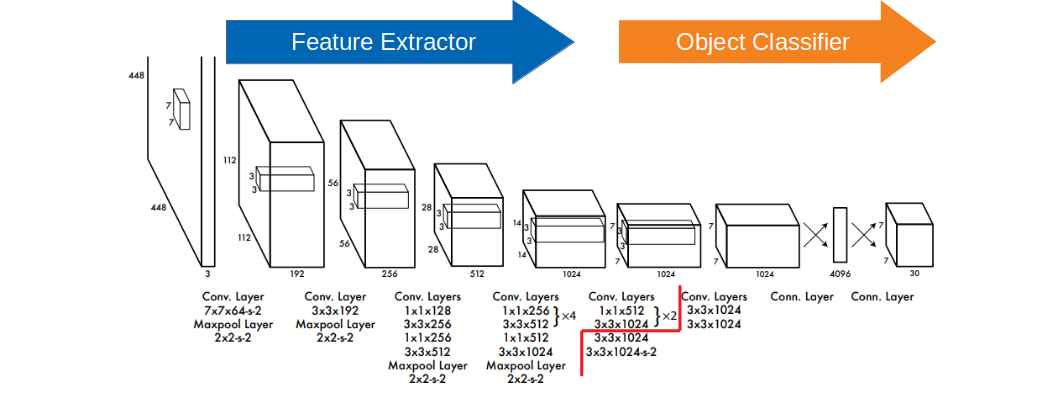
整個卷積特徵提取結構中,在上圖中紅線切分之左側以前,是以大型dataset(e.g. ImageNet)先pretrain過。而在訓練YOLO的時候,這段會固定下來而不修正這裡的權重,只訓練後半段的部分(後半段要接分類檢測器的部分與分類器)。
而到了最後的輸出層進行判斷的時候,我這裡一樣用具象化的圖解來呈現:
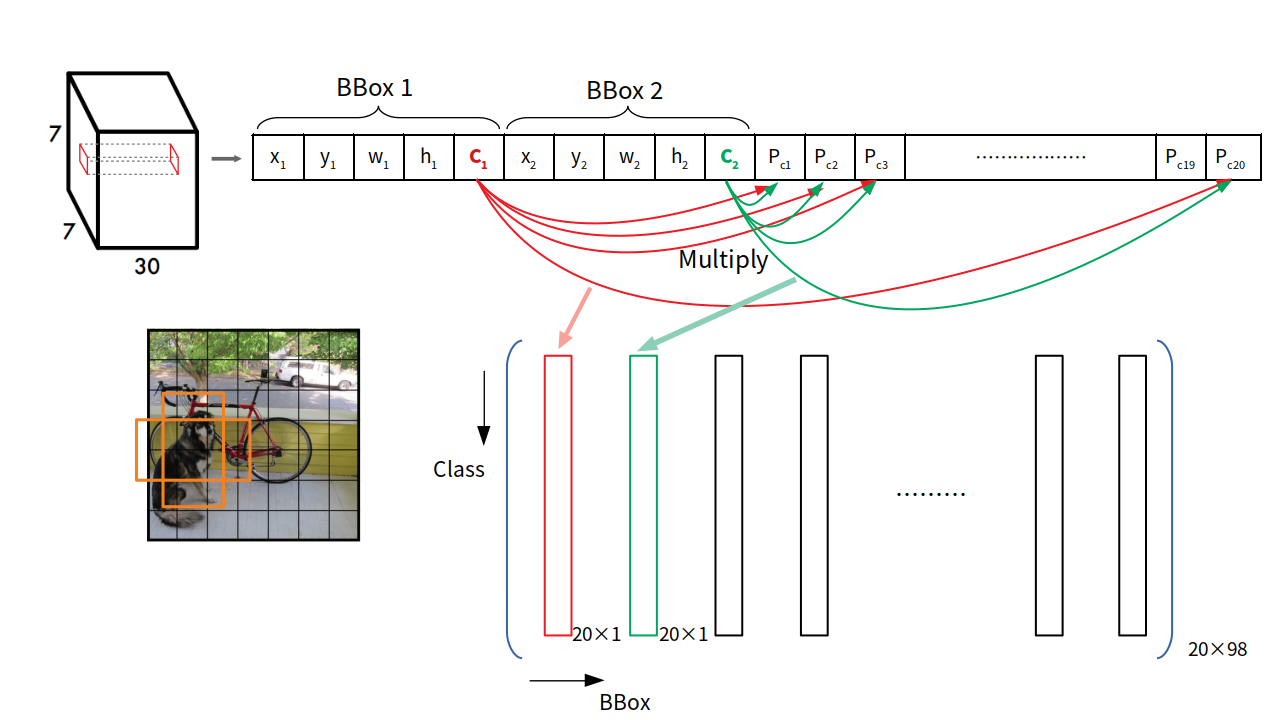
如上面說的,一個格子裡兩個邊界框,所以作者藉由將兩個邊界框的置信度,分別乘進後面所接的類別機率陣列,作為最後評估邊界框的指數。也就是說,每一個邊界框都會產生一條20x1的評估指數陣列。所以將2×49=98個邊界框的陣列排在一起,就會形成縱軸代表各個類別,橫軸代表邊界框編號的矩陣。
Loss function
在損失函數的設計,作者採用的是平方和的方式計算。誤差在這裡的來源有分類上以及邊界框兩種。而經過上面的解釋應該很容易發現,其實大部分的位置上,邊界框都是沒有包含物體的。
沒有物體的邊界框,會出現confidence很低,把最終指標推向幾乎等於0的數值,而導致誤差梯度太大,整個損失函數被沒有物體的邊界框給主導,而使得損失不穩定而難以訓練得好。因此除了將損失分成來自分類與邊界框以外,還要讓有、無包含物體的邊界框分開計算,並且賦予不同的權重。下式就是YOLOv1的整個損失函數全貌:
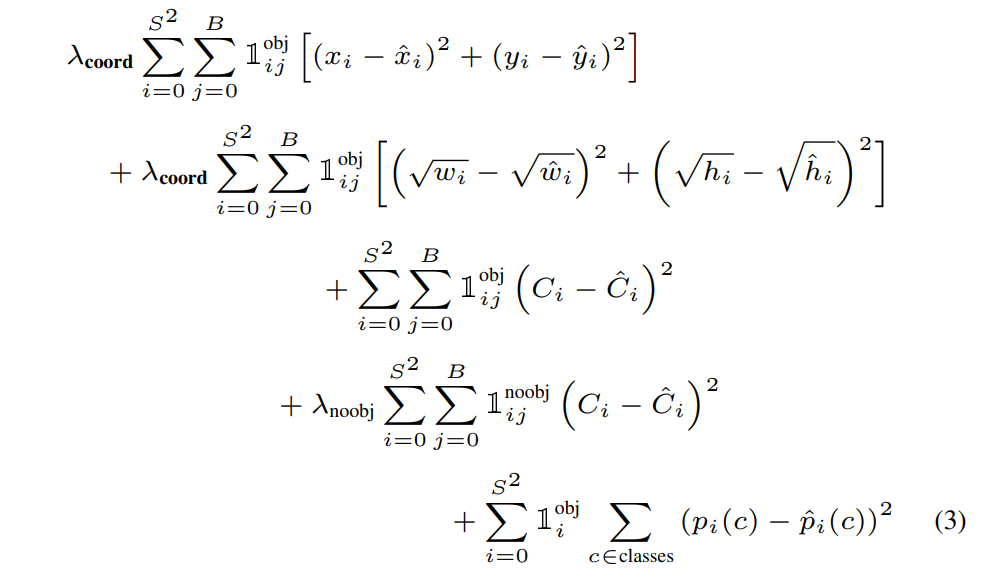

至於,w、h為何要取根號,則是因為大框和小框對於誤差量的反應比例不同,在損失函數上也應該反映出這一點,才將寬度和高度的值取了根號才相減。
Detection
當我們訓練完了,在偵測階段,我們在網路的最後獲得了98個邊界框對應到各個類別的評估指數,縱軸是類別,橫軸是邊界框(忘記的話可以看上面那張圖)。那我們要怎麼篩選出最後的那些邊界框呢?
當然還是透過NMS!但是在這之前還需要進行排序的動作。假定第一個類別是狗,則我們會將第一列上的邊界框依照評估指數的高低排序,才將這些邊界框運行NMS的計算,IoU高於門檻值的就強制為0,直到剩下的邊界框評估指數都變成0為止。

結論
YOLO v1用非常直覺的方式設計了網路的輸出,讓網路就是要同時給我分類的機率還有邊界框在哪裡,所以整個網路的架構非常簡潔易懂,更重要的是速度比彎彎繞繞的two-stage模型快上好幾倍,可以達到45 fps!而且其mAP還比R-CNN好很多。雖然很快,但是有不少缺點:
- 對於群聚的小物件偵測能力不佳,因為每個格子只有2個候選邊界框且只能對應到1個類別。
- 因為是由訓練資料中學習辨識與邊界框,所以對於沒看過且擁有怪異長寬比的物體,將難以捕捉。
- 在經過多個降維後,只在特徵解析度最粗糙的feature map上進行邊界框的預測,效果並無法太好。
- 對於大的bbox和小的bbox在loss的反應上配比不佳,小的對IoU反應應較劇烈。
下一代的YOLO v2是一個大躍進,讓表現突飛猛進,同時在偵測速度上甚至可以達到60 fps以上,是真的real-time,這就等待下回分曉!
這是我個人對這篇論文的消化,如果有錯誤之處,請各位朋友指教或幫我指出
如果喜歡這篇文章,記得在下面幫我按個Recommend↓
謝謝~
留言