
[物件偵測] S5: YOLO v2 簡介
前言
YOLO v1 用非常直覺的方式設計了網路的運作,讓網路從輸出到輸入直接給出分類的機率與邊界框的位置,而且速度遠遠比two stage的模型要快得多。不過準確度卻還差強人意。因此YOLO v2這次參考了Faster R-CNN中anchor的概念而做了改進,也對feature map的使用做了改善。這次我們就談談這些改進。
論文:
YOLO9000: better, faster, stronger
演算法架構
大抵上來說,YOLO v2並沒有對v1的網路架構做太多的更動,而是在一些細節上做改進,使得網路在對於物體的定位精度高很多,在PASCAL VOC的mAP表現可以來到78.6的成績。以下我們就分成backbone、anchor和feature map說明。
Backbone
為了要修正v1的一些缺陷,如在Recall上的低落與對於物體位置辨識的錯誤,YOLO v2首先在backbone網路上做了改良。作者提出了Darknet-19的網路架構:
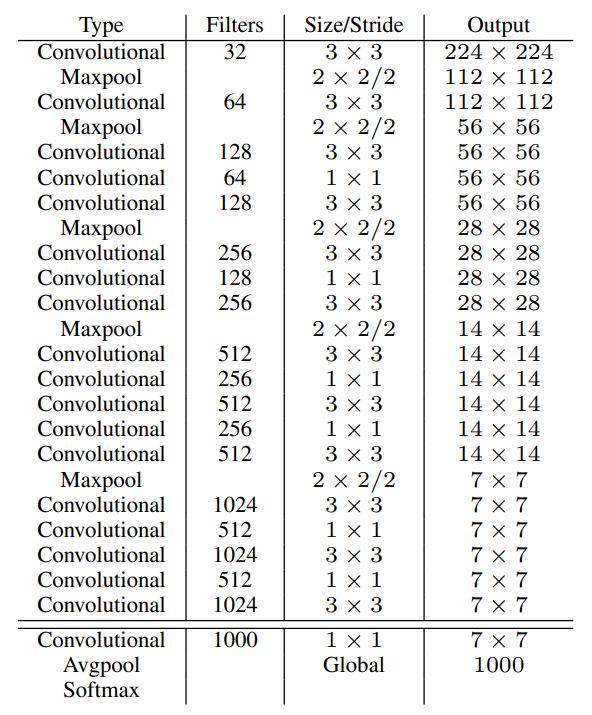
Darknet-19
很明顯可以看到,darknet-19的設計主要的參考依據就是VGG-16,因為VGG-16其實相當好架設,也非常有效。不過最大的缺點就是最後的兩層全連階層使得運算的參數量過高。所以darknet-19的設計又參考了Googlenet和Network In Network的設計,運用1×1的卷積和全域平均池化,來取代掉原本分類層的設計,讓參數的使用量只需原本VGG-16的0.28倍。
與此同時,darknet-19也引入了batch normalization的設計。因為隨著網路的加深,內部參數的統計量在每一層的傳遞中一直改變而越來越難訓練。因此加入batch normalization除了穩定並加速深層網路的訓練,同時也起到了regularization的效果。
Anchor
在邊界框的設計上,YOLO v1是將邊界框的x, y, w, h直接作為輸出進行預測。然而anchor box的設計則是預測anchor的偏差量,這樣的方式其實簡化了邊界框的預測問題(因為可以針對既有比例和尺寸的邊界框做微調,而不是從
甚麼根據都沒有就直接預測),也讓一開始的誤差一定程度的控制下來而使得網路更好訓練。
而如何決定一開始的anchor,作者就利用K-means法來對既有的邊界框做clustering,並利用IoU來評估,發現選出5個anchor就可以在模型的recall和計算量之間取得平衡。
不過直接套用anchor進來,還會遇到一個問題是,anchor的x, y在計算預測值和實際值的偏差\(t_{x}\), \(t_{y}\)時,沒有限制式來限制值域範圍(如下式),因此在訓練的初始階段,loss會跳動的較劇烈。
\[x = (t_{x}*w_{a}) - x_{a}\]
\[y = (t_{y}*h_{a}) - y_{a}\]
因此,作者將邊界框中心點偏差量\(t_{x}\), \(t_{y}\)的定義改成是對其所在的feature map的cell之左上角的點的偏差量來描述之,如下圖。這樣就可以把\(t_{x}\), \(t_{y}\)的值域確實限制在0, 1之間。圖中的\(p_w\)和\(p_h\)是anchor的寬高。
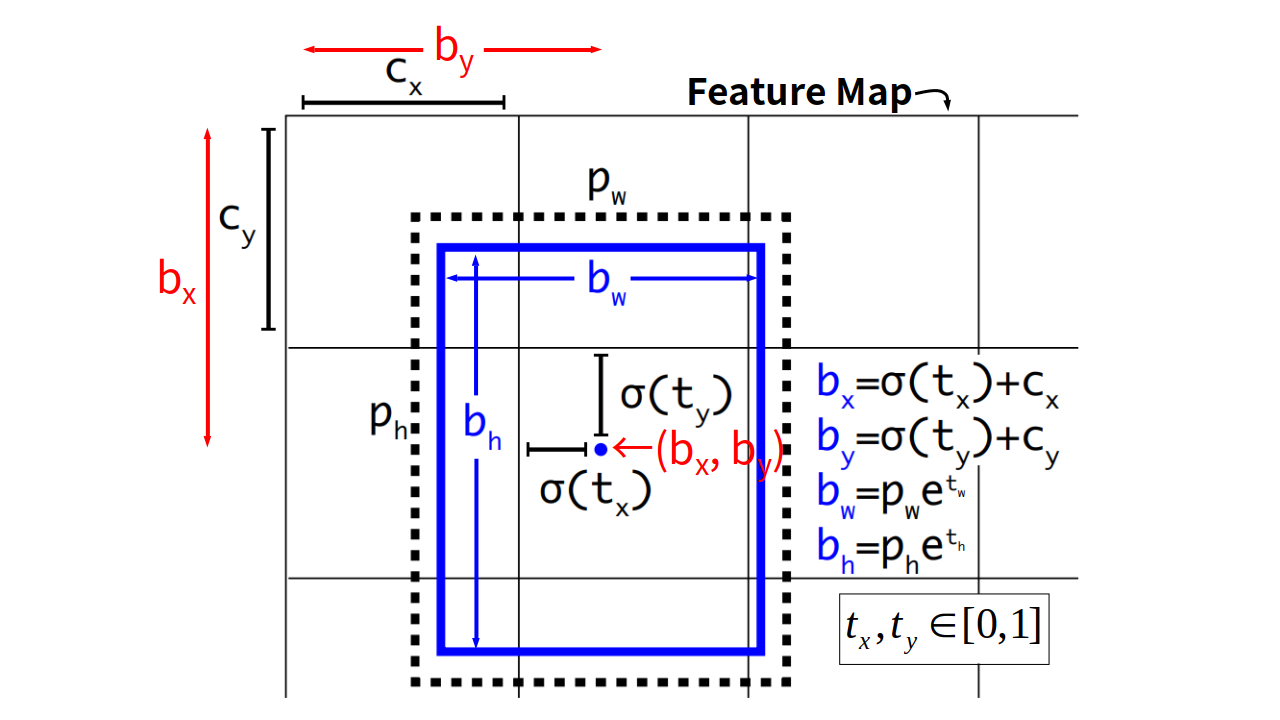
因此,在邊界框的四個位置資訊和confidence的預測式就可以寫成:
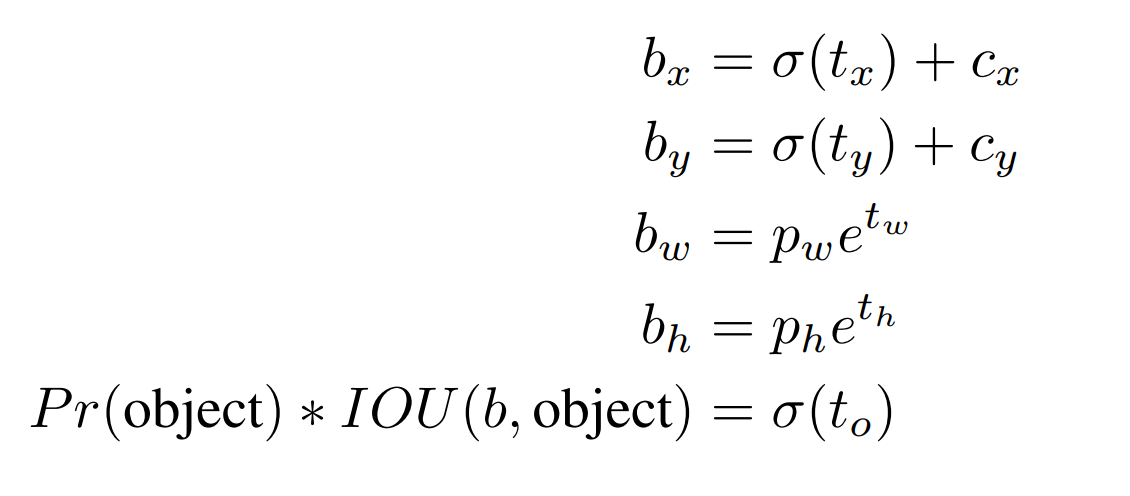
Feature map
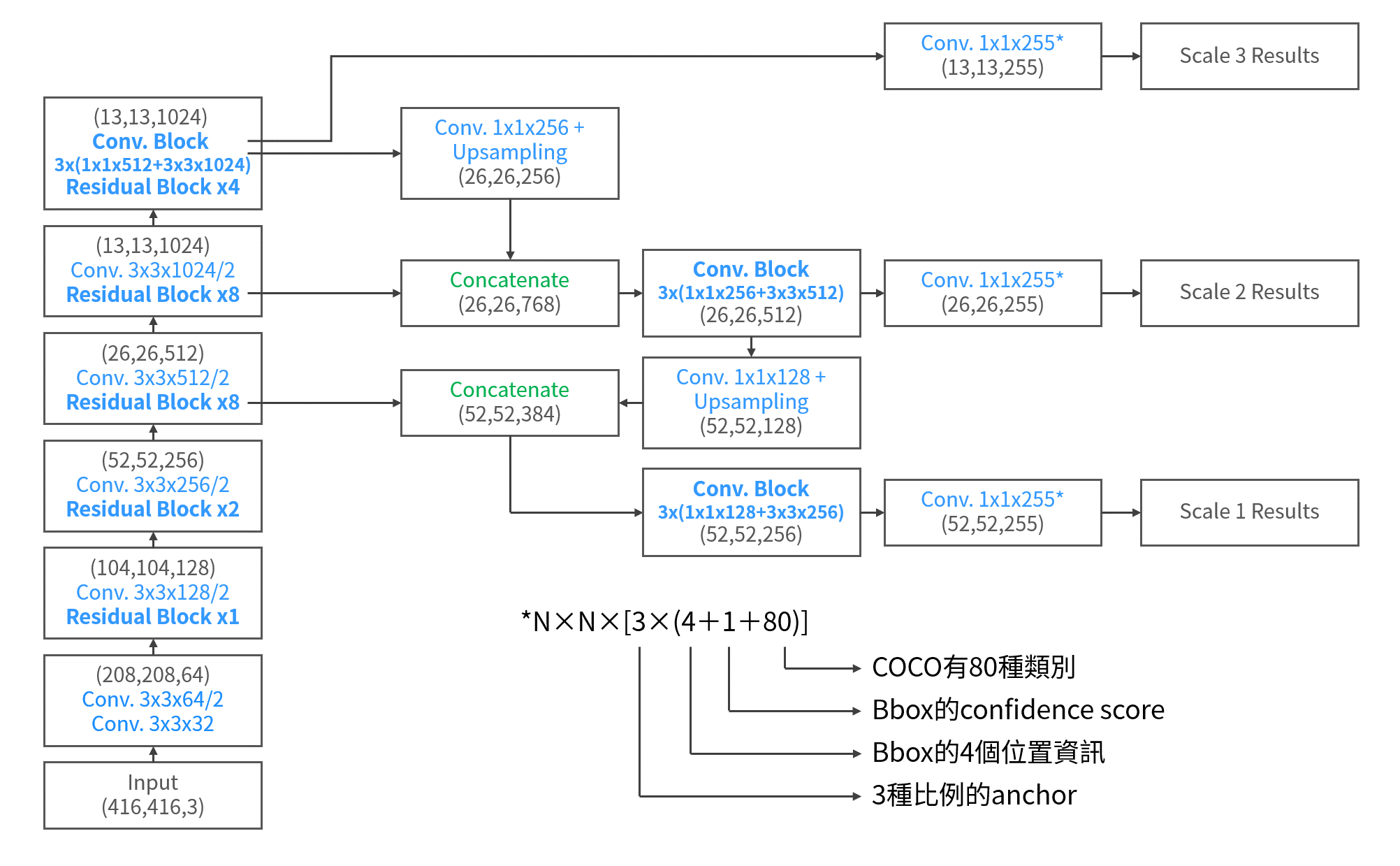
在使用feature map的方式上,為了避免直接使用pooling造成的訊息消失問題,作者運用了一個拆分組合的方式來產生要使用的feature map,具體來說就像下面這張圖一樣:
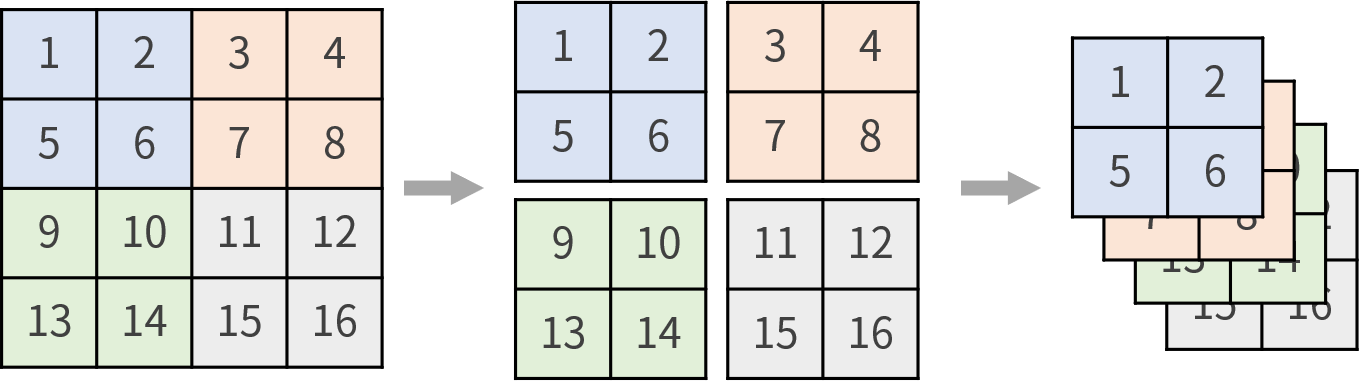
也就是說,YOLO v2中倒數第二個feature map是26×26×512,經過pooling後就變成13×13×512,並不是就這樣結束了,而是把原本26×26×512拆成4份,變成13×13×(512×4),並且接在13×13的feature map,如此就將兩種不同尺度的feature map都考慮到了。
結論
以上是YOLO v2在網路設計部份的改進,考量了anchor的設計之後,以VOC資料集為例,anchor有5種,每個邊界框有4個偏移量和1個置信值(\(t_x\), \(t_y\), \(t_w\), \(t_h\), \(t_c\)),加上各自都有對應到20個類別,所以v2的輸出維度就是13×13×5×(5+20)。
雖然論文當中還有提到一些更細節再training上的方法,例如multi-scale、world tree的訓練、但這邊並不難理解就不再提。v2 加上了anchor的設計並且調適成適合one stage模型的方式,除了在速度上最快可以來到60 fps以上,當時真的是非常驚人的結果。不過依然存在著缺陷是還是考慮太少尺度的feature map來做偵測, 因此如果將這部分也考慮了進去,對於影像中各個大小的物體就能以合適的尺度去做偵測。這部分就是第3代的YOLO v3。
這是我個人對這篇論文的消化,如果有錯誤之處,請各位朋友指教或幫我指出
如果喜歡這篇文章,記得在下面幫我按個Recommend↓
謝謝~
留言