
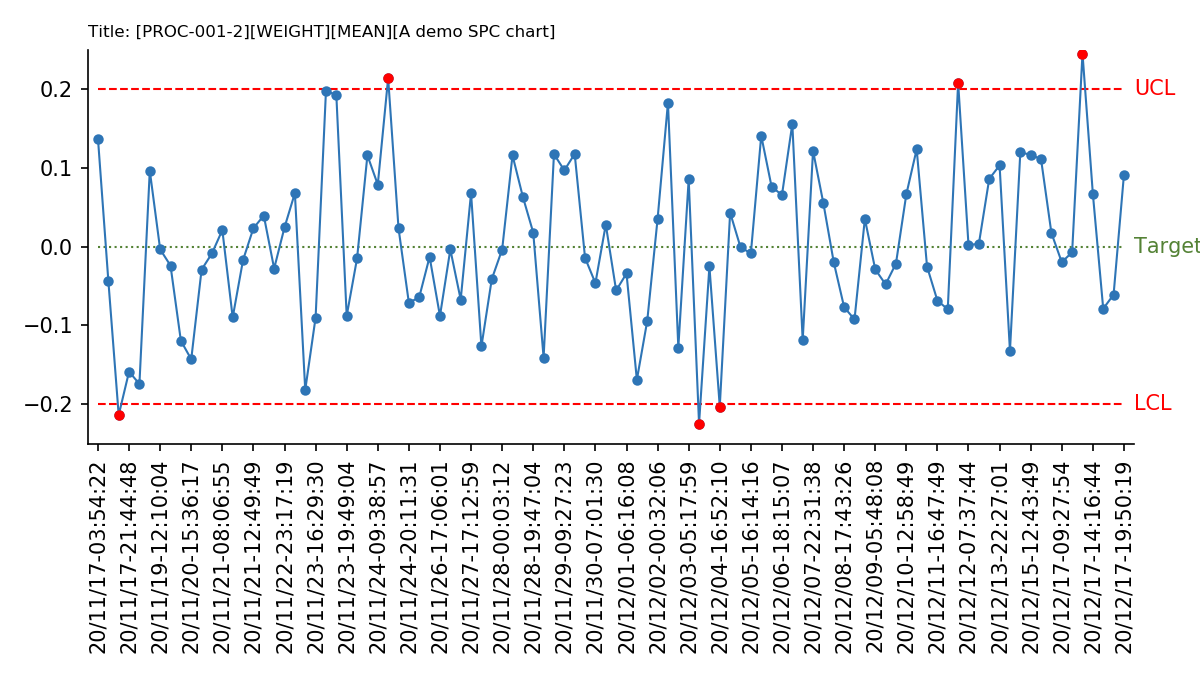
[物件偵測] S6: SSD 簡介
前言
在two-stage模型中,雖然發展到了Faster R-CNN利用兩個網路來進行物件偵測已經相當成熟,但是網路的架構龐大、構造複雜,運算時間也是難以達到真正的real-time運用。而SSD作為一個在2016年發表的相當經典的one-stage模型,一樣透過一個一條龍的完成物件的分類和定位。他用的方法也是吸收了類似Faster R-CNN中anchor的概念,名叫default box來處理邊界框的問題,也使用了影像金字塔的概念來運用不同尺度的feature maps,讓網路對於不同尺度的特徵都能夠有所考量。
論文:
SSD: Single Shot MultiBox Detector
演算法架構
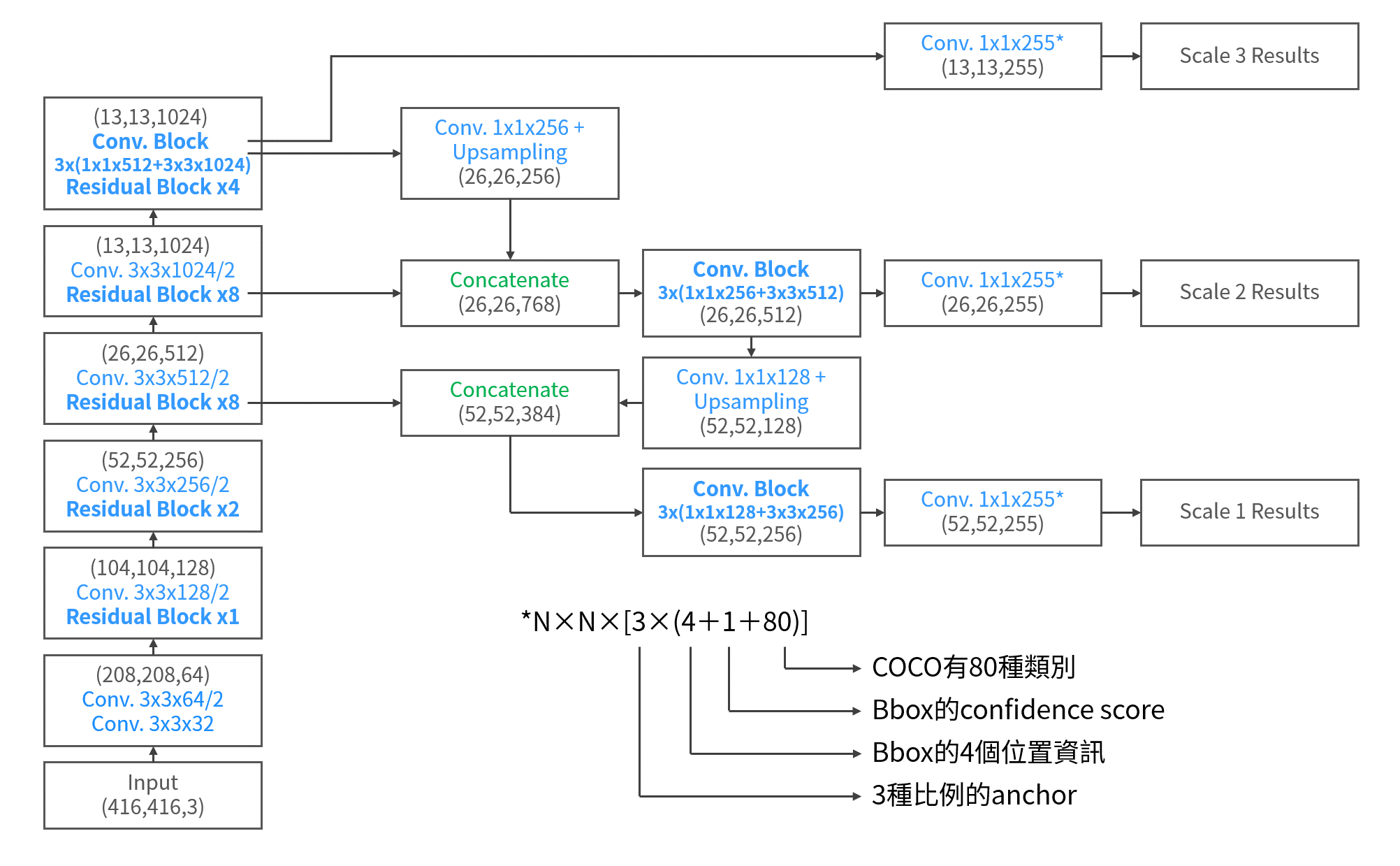
作為one-stage模型,SSD以VGG-16為整個模型的主幹,在不同尺度的feature maps下進行辨識的工作,這樣的機制被稱為 Pyramidal Feature Hierarchy。整個網路架構如下圖所示
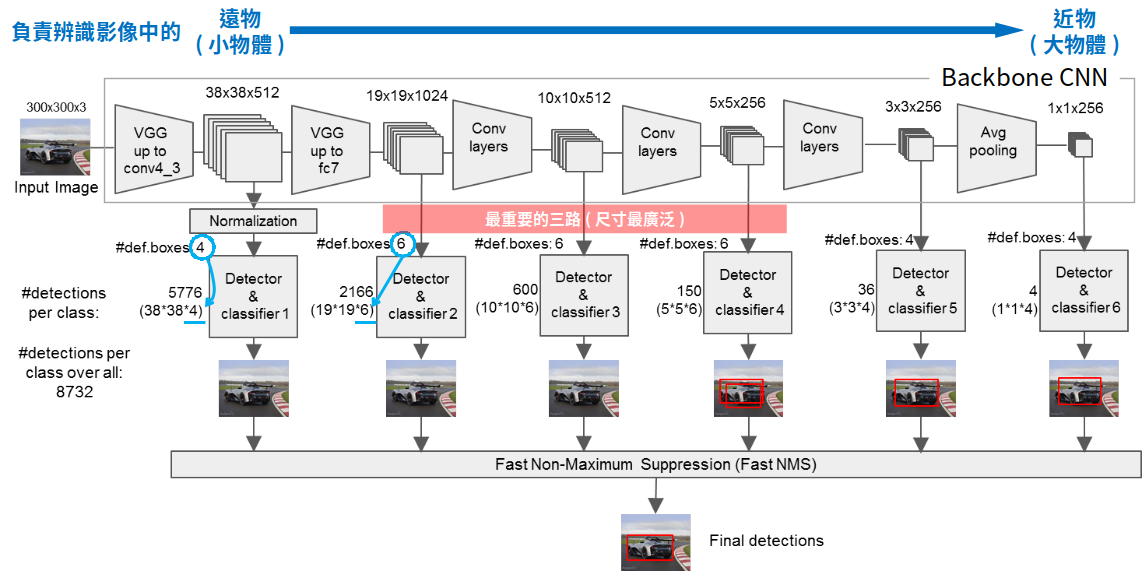
SSD overview
從VGG-16的conv4_3層之後,以38×38×512開始,每次降維之後的feature maps都會用來做detection用,就像圖中的分支所示。每一個支線,都會有各自的detection和classifier. 在SSD中,共有6條支線來處理不同尺度。隨著維度的降低,所處理的物體在影像中所佔有的比例是由小到大。
接著,就是如何將這些支線用來處理邊界框的問題了
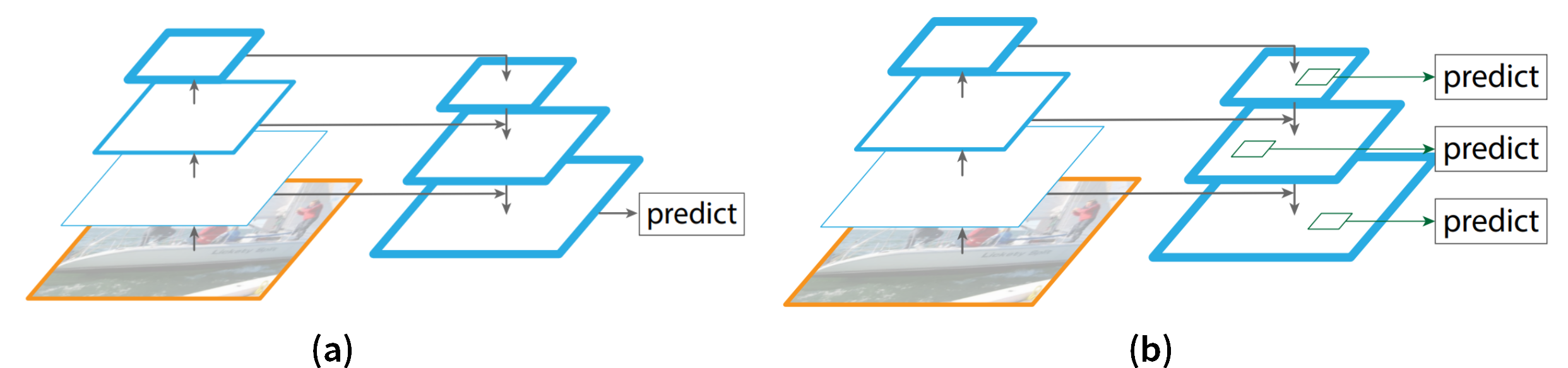
Default box
SSD中的default box就如論文中的圖中所示:
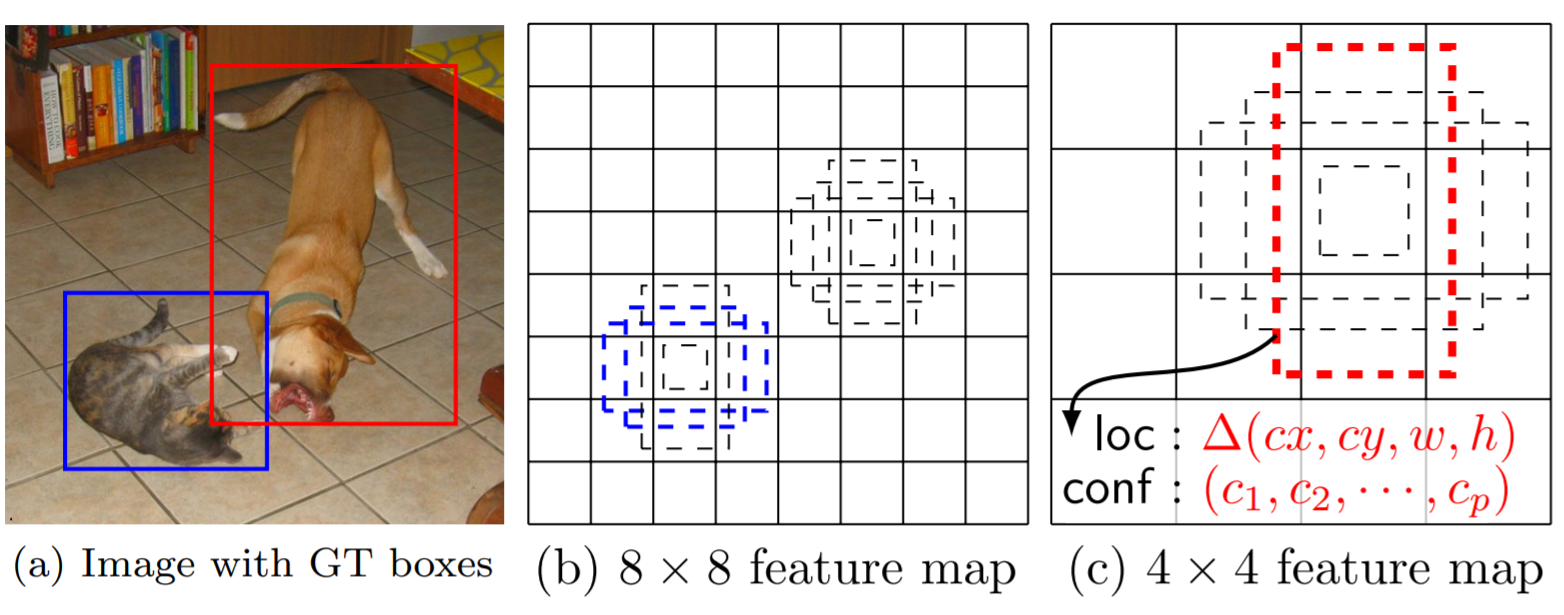
default box
Default box在SSD中是由兩個參數產生,一個是scale,另一個是ratio。scale代表不同的feature map上,你的default box與原始影像的大小的比例關係。令最底層的feature map的scale是 \(s_{min}=0.2\), 最高層的則是\(s_{max}=0.95\)。則中間的其他feature map的scale就利用下面這個式子計算:
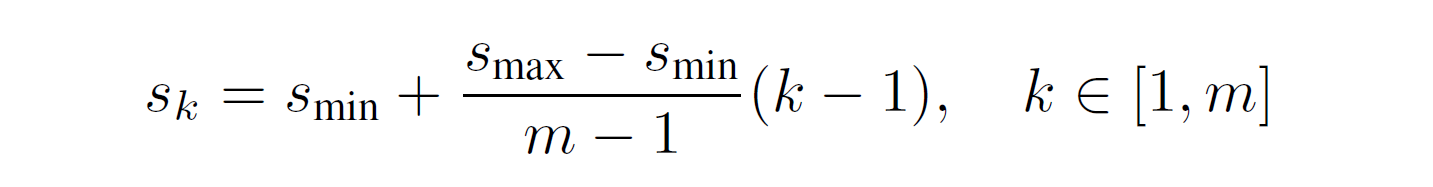
Ratio則是決定default box的比例,搭配scale的值來決定default box的寬度和高度。不過,對於長寬比是1的情況,SSD會再計算出一個更小尺度、長寬比是1的box。到這邊,default box看起來和anchor非常像。以圖中為例,比例就有三種。而如果你看到SSD overview這張圖,就可以發現每個階段的比例有4, 6, 6, 6, 4, 4種。你可以針對想辨識的物體類型給予不同數量的比例。SDD在中間幾個feature map都給了6種比例來辨識,就是因為對於一般的物體在影像中的占比會是以中間這三層的尺度最為多數。
Detector
取出了feature map之後,SSD會讓它先通過一次3×3的卷積來得到真正用來作為detector的神經層。而卷積的深度就是和剛剛default box有關。若假定default box數量是D,而目標類別有C個類別,邊界框有4個值(x座標,y座標,w寬度,h高度)的偏差量(offsets),所以深度的計算就是等於D×(4+C)。
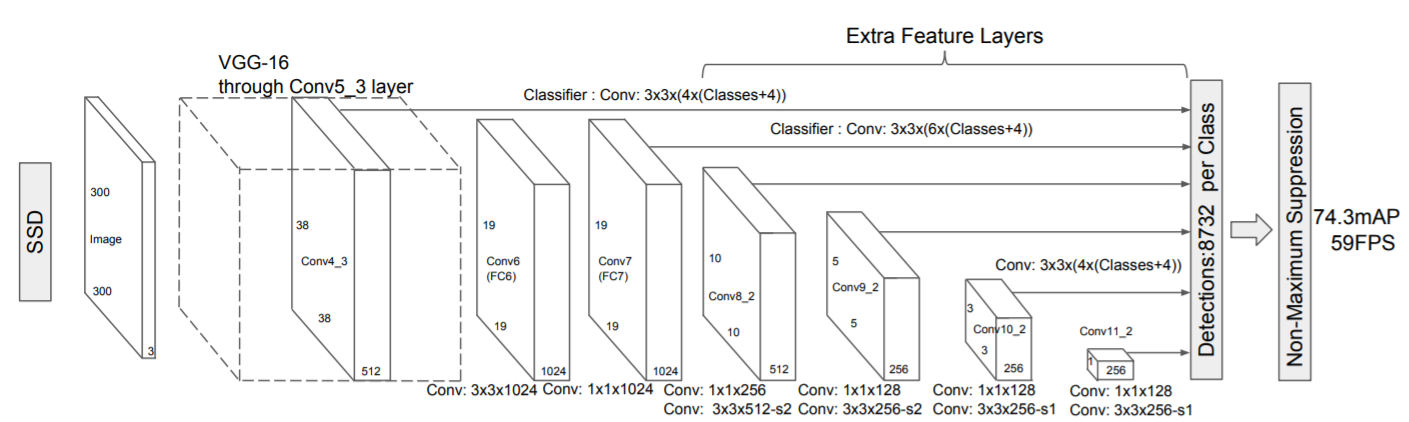
我們可以將這個map在深度上D×(4+C),拆成邊界框的定位(localization)和分類(classification),如下圖所示。每一個default box都會有各自的分類分數(i.e. 論文中的class confidence)和邊界框的offsets,將default box套用這些offsets之後,成為輸出的邊界框。而與ground truth box的IoU大於0.5的default box,則稱default box 和 ground truth box 為匹配的。
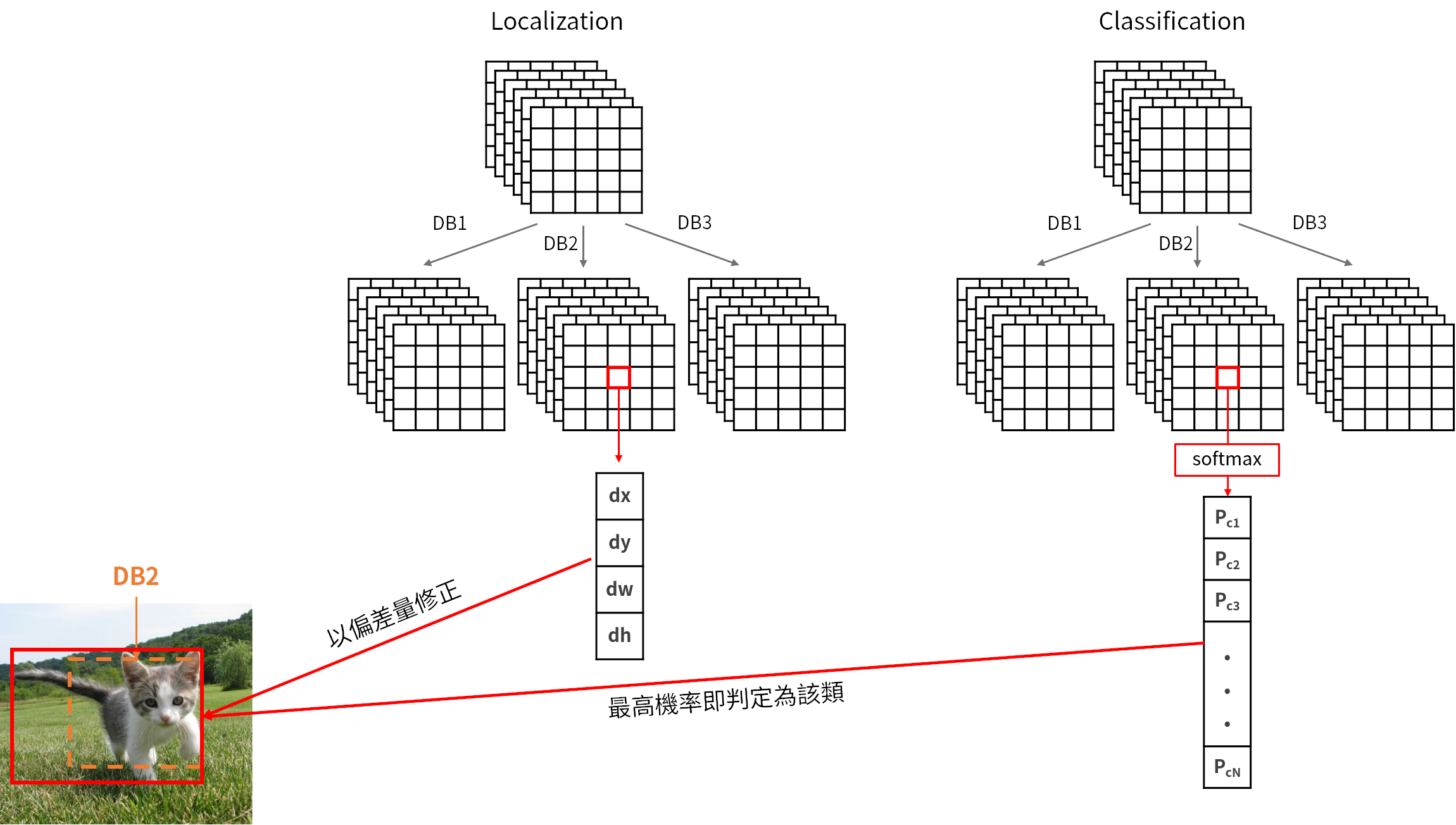
Training
SSD的訓練同樣會將一個批次中的樣本分成正樣本(positive examples)和負樣本(negative examples),且比例為1:3。然而,在大多數的default box都是負樣本的情況下,選取負樣本的方式是,依照這些default box的分類分數c的損失\(\log{(\hat{c}_{i}^{0})}\)來決定,其中:
\[\hat{c}_{i}^{0}=\frac{exp(c_i^0)}{\sum_{p}exp(c_i^p)} \]
在SSD中,會藉由將計算這些不包含物體的default box的\(\log{(\hat{c}_{i}^{0})}\)由高到低來排序,並且選出最大的幾個來搭配positive examples的數量作為一個批次進行訓練。
而接下來介紹在整個訓練的loss function的部份,整個訓練的loss一樣是由分類和邊界框兩種來源構成。先說分類的損失,若我們以 \(x^p_{ij}\) 來代表第 i 個default box和屬於p類的第 j 個ground truth box的匹配情況(匹配為1,反之為0),則分類損失 \(L_{conf}(x, c)\) 就是考量了正樣本的和負樣本的分類誤差之和:
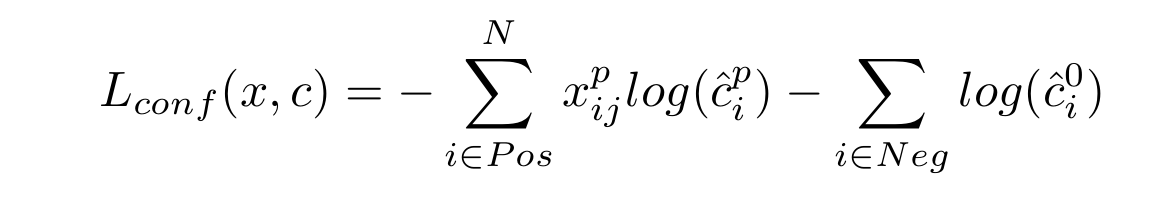
而在邊界框方面,則和Fast/Faster R-CNN很像,只考慮正樣本的default box,並用Smooth L1來設計這部分的loss function:
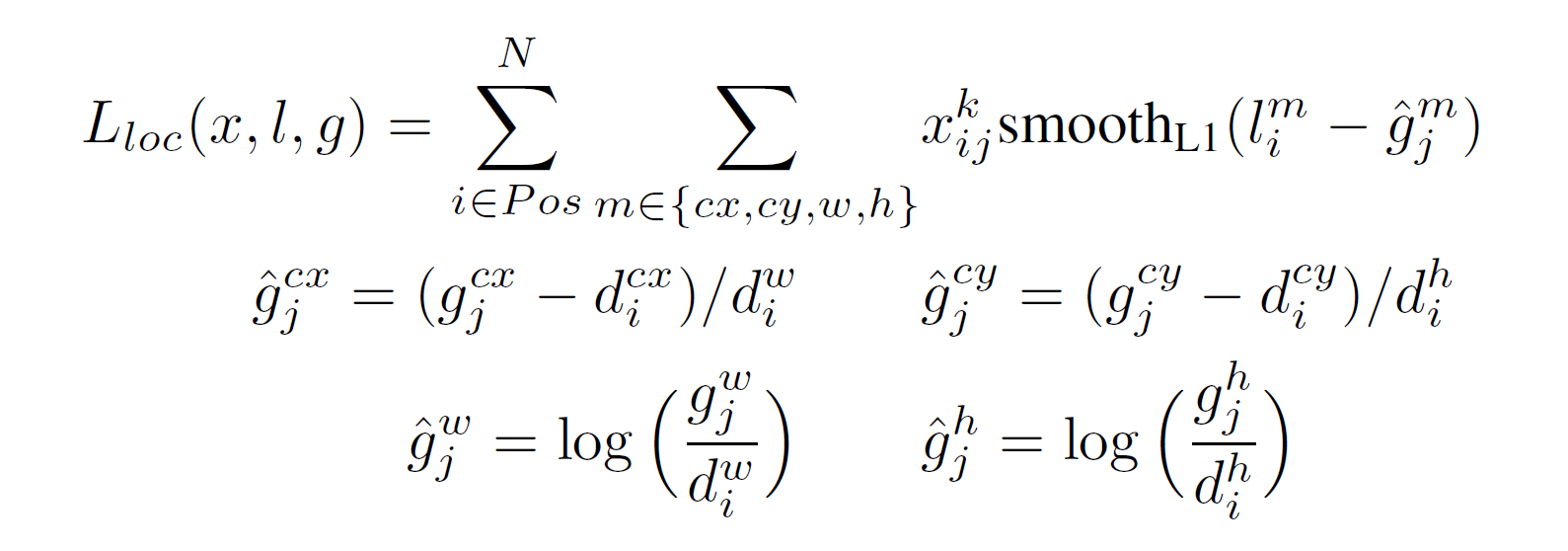
所以完整的loss function即為兩項的加權和:
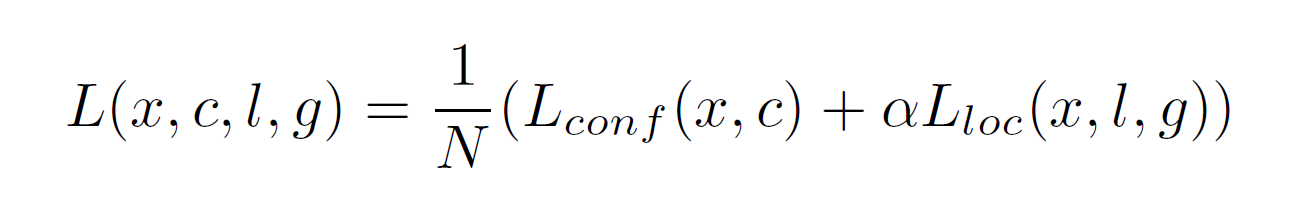
其中,N是匹配的default box總數,\(\alpha\)就是邊界框項的權重,預設為1。
結論
SSD把他的挑戰目標放在Faster R-CNN和YOLO v1身上,根據他所設計的整個網路架構,算是突破兩這兩個模型的缺點,在PASCAL VOC 2007資料集上,輸入影像為300×300的SSD (SSD300)可以達到的74.3的mAP與46FPS的偵測速度表現。One-stage模型能有這樣的表現確實是讓大家驚豔。雖然SSD並沒有提出甚麼太驚人的演算法進展,但是我認為他的精度提升的最大原因是採用了多尺度的feature map進行辨識,搭配上為數不一的default box配置,讓整個網路所產生的候選框數量相比其他網路都要多,也就多了很多可能性。
這是我個人對這篇論文的消化,如果有錯誤之處,請各位朋友指教或幫我指出
如果喜歡這篇文章,記得在下面幫我按個Recommend↓
謝謝~
留言