
[物件偵測] S7: FCN for Semantic Segmentation 簡介
前言
拖了很久才繼續產出新的介紹文分享給大家。這次要來說說物件辨識發展的過程中也佔有一席之地的Semantic Segmentation是什麼,以及這其中代表的方法—Fully Convolutional Networks (FCN)是怎麼透過全卷積的網路來實現這個目標的。
論文:
Fully convolutional networks for semantic segmentation
何謂Semantic Segmentation
以物件偵測的發展目標來看,我們可以知道有大概幾種演進目標:
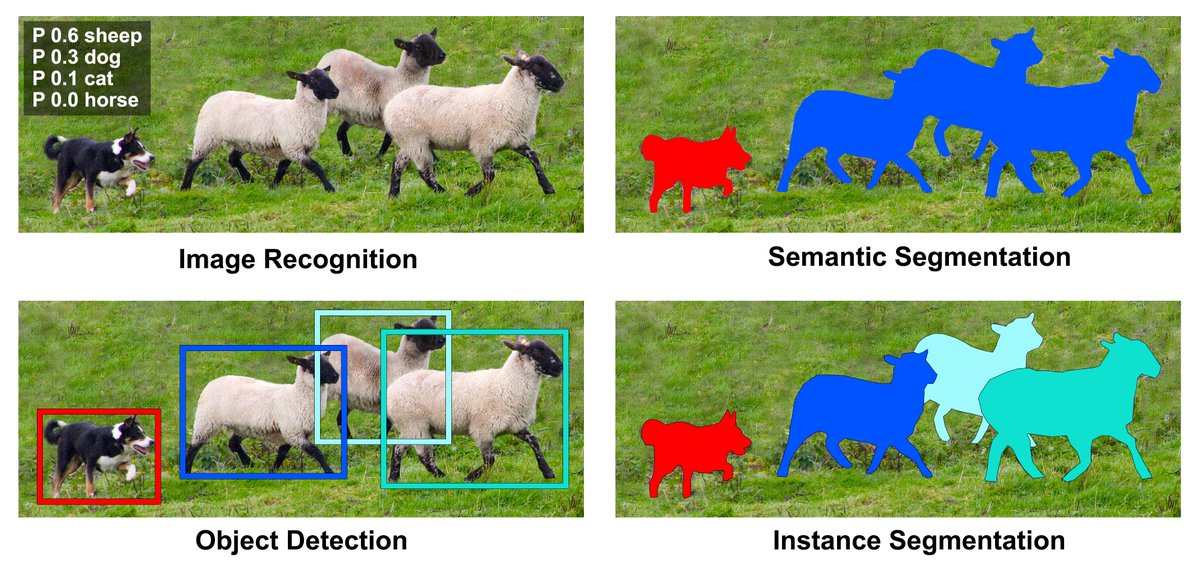
- 影像辨識 (Image Classification):最一開始,我們希望能夠知道一張影像中所含有的物體是什麼,因而發展出影像辨識的技術。以上圖中的左上來說,我們會想知道這張圖片,包含哪一種動物的機率機率最高,這張照片就是該動物。而在深度學習中,以CNN最為經典。
- 物體定位 (Object Localization):但是,當一張照片裡有好多種物體要區分,怎麼辦?所以我們要將每一種物體都標示出來,同時區分他們所屬的類別。以上圖中的左下為例,我們要將不同的羊和單獨的一隻狗,都分辨出來,並且知道他們的位置。這個部份,也就是我之前介紹的那些物件偵測的經典方法(Faster R-CNN, SSD, YOLO, …)在做的事。
- 意義分割 (Semantic Segmentation):既然能作到物體定位,應該也能知道這張影像上,每一個像素是屬於哪一種類別而將這些不同類別的像素區分開來吧?這就是意義分割(中文應該翻作語意分割,但這裡是用在影像上所以我不喜歡叫它「語意」)在做的事情,如同上圖中的右上。
- 實例分割 (Instance Segmentation):然而,我們看到在上圖中Semantic Segmentation的例子,可以發現不同的羊因為他們的像素都被歸類成「羊」這個類別,所以無法區分出他們的個體,所以其實Semantic Segmentation這個方向有時候對結果來說並不是很好。我們想要的,應該要是像上面這張圖中的右下圖,可以區別出各自的個體的分割和位置。
透過上面這四項名詞解釋,算是簡單區分出物件偵測對於找出物體的方式如何變化有一定的了解。對於要做物件偵測這件事來說,Instance Segmentation其實是Semantic Segmentation和Object Localization兩個方向的整合。最有名的例子當屬Mask R-CNN。不過,這個模型我們之後再提。先來了解一下Semantic Segmentation中的代表作—FCN,會對之後理解Mask R-CNN大有幫助。
演算法架構
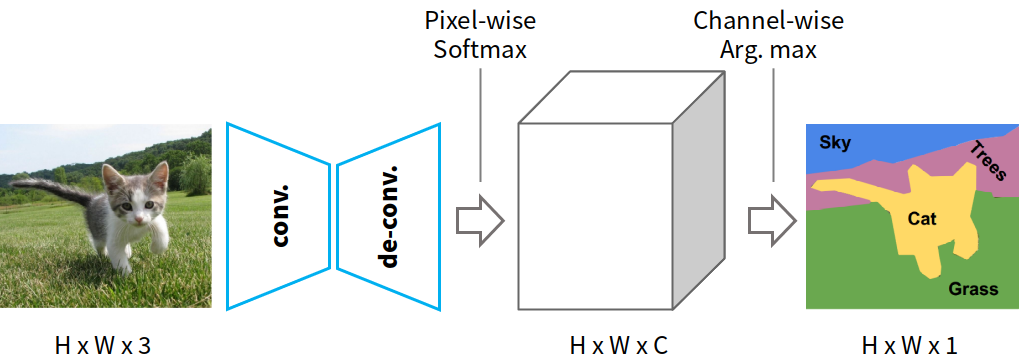 Fig-01
Fig-01
論文中的圖一其實只把前半段畫出來而已,重要的都沒畫到XD,所以這裡我自己做了一個簡單的示意圖。下面就一個個來說明吧。
全卷積網路
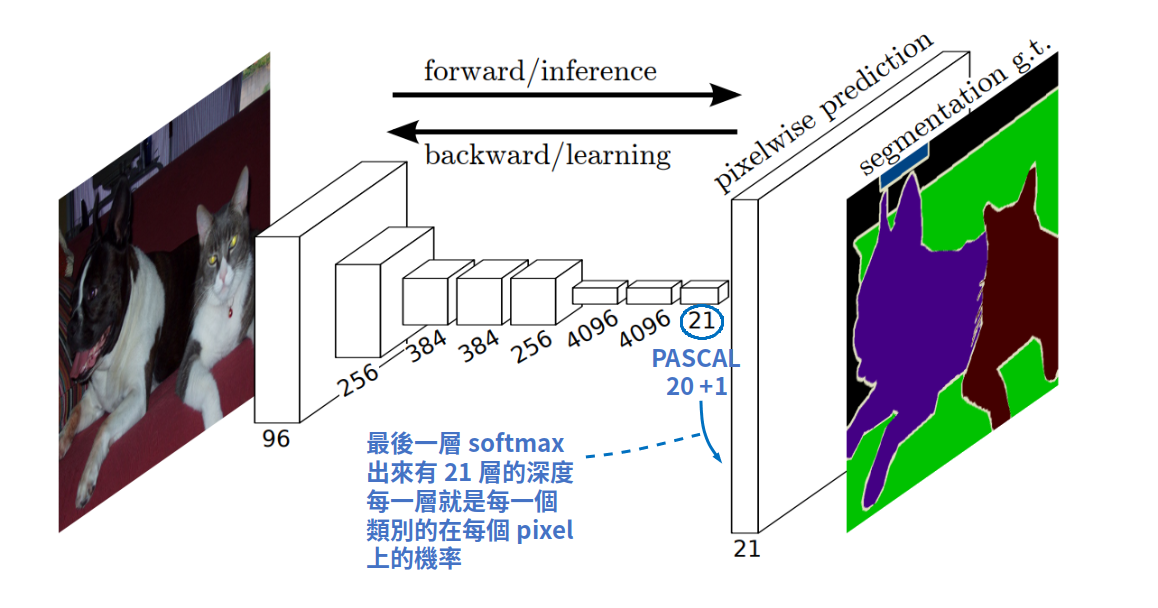 Fig-02
Fig-02
在卷積網路(指的是Fig-01中conv.)的部份,我就以Fig-02(論文中的圖一)來說就好。可以看到它將正常的卷積網路結構化了出來。而所謂全卷積網路就是說最後的分類層從原本的全連接層改成也用卷積層處理。這麼做的原因是因為,以往以全連接層的方式,在處理Semantic Segmentation的問題的時候,因為丟棄了空間維度的訊息,所以無法對像素之間的關聯性有很好的處理。因此,改以卷積處理,並在最後加上softmax活化函數,才能輸出每個像素屬於各個類別的機率,也就是segmentation最粗略的prediction map。在論文中,作者是使用10×10的尺寸作為最後輸出大小。當然,在最後的卷積層的輸出深度,也就等於目標類別的數量,PASCAL VOC是20類+背景,所以是21。
Upsampling
但是,因為卷積網路不斷降維的關係,影像從原始維度降到這麼小,要怎麼將prediction map的維度還原回到原始尺度上呢?最直覺的想法就是把卷積網路的最後輸出給放大回來,也就是upsampling。Upsampling又可以分為單純以插值方式放大影像的upsampling,以及以卷積反操作的反卷積(deconvolution)所獲得的放大影像,還有一種是針對pooling layer記錄其位置而反推回去的unpooling。
而其中,一般插值方式的upsampling當然最容易遭受到解析力不足的問題所以不好。那反卷積是怎麼一回事?
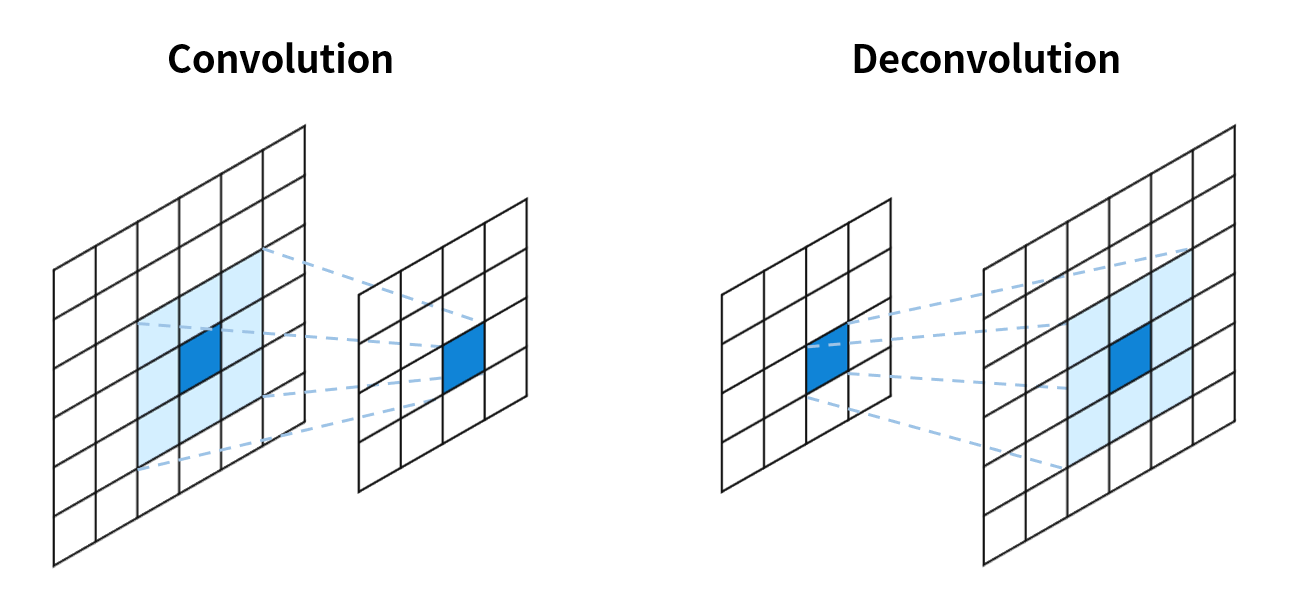 Fig-03
Fig-03
Fig-03這張圖是一般卷積和反卷積的示意圖。反卷積,顧名思義是要將卷積的結果反轉回來,但是其實反卷積做的事情跟卷積運算方法是一模一樣的!怎麼說一樣的呢?下面這張圖(Fig-04)我認為很好地說明了反卷積的運作。你可以看到反卷積基本上就是利用padding的方式擴大要反卷積的影像,然後一樣用卷積核做卷積來放大影像。而反卷積中的卷積核當然是待訓練的項,在初始化階段,會先以雙線性內插(Bilinear interpolation)初始化放大後的影像,再讓網路去修正卷積權重。
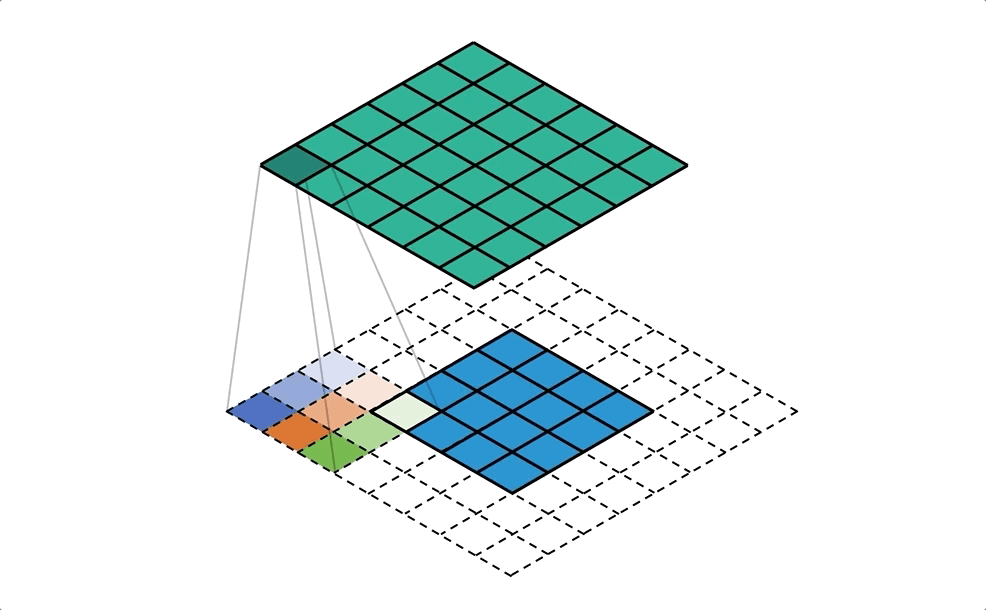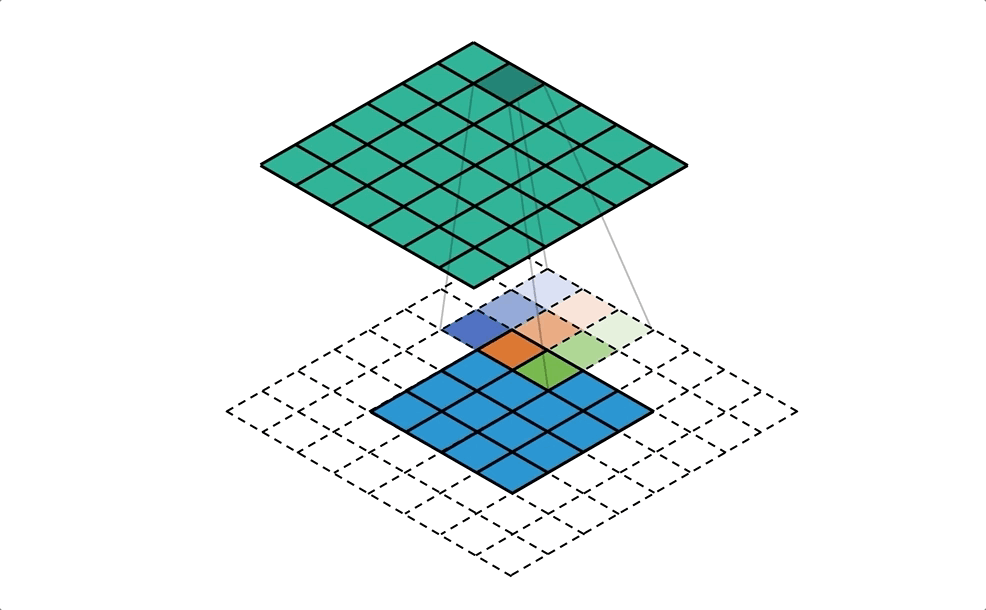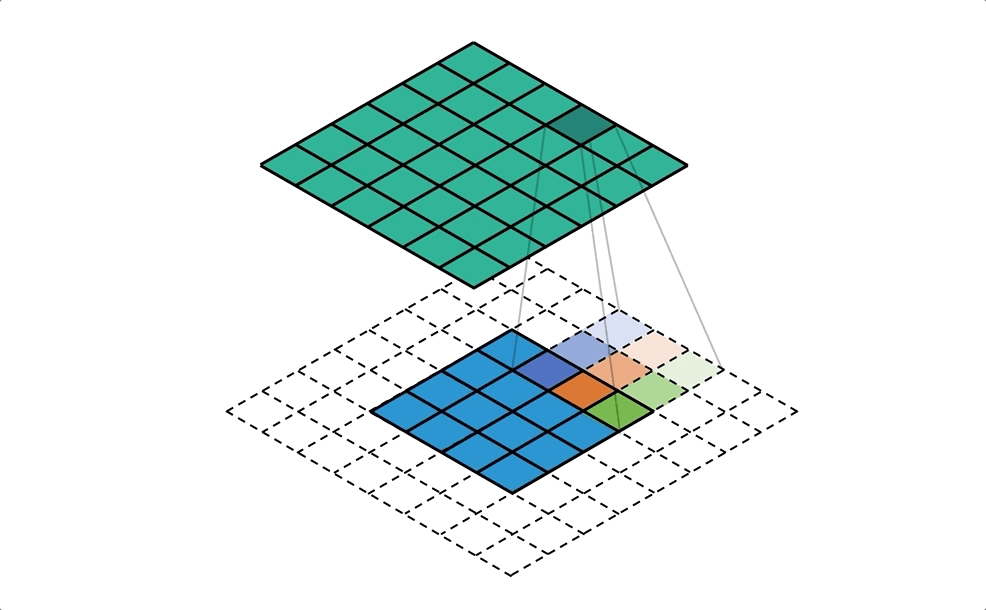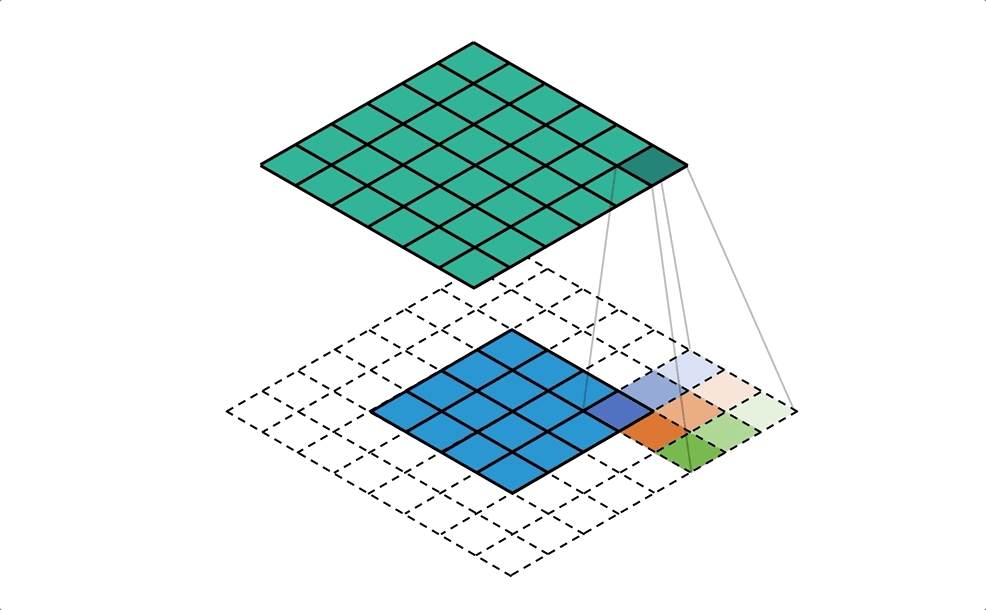 Fig-04. Quoted from here.
Fig-04. Quoted from here.
而在順向的卷積網路中,通常伴隨著許多階段的池化(pooling)將影像維度逐步縮小。然而現在FCN要將小尺寸的prediction map放大回來,如果直接從最小的prediction map放大回來,結果會是很差的(如Fig-05最左)。
 Fig-05
Fig-05
因此,需要將逐步pooling的這些feature map在放大的時候也考慮進來,才能夠使得放大的過程中,融合了不同尺度下的特徵而獲得較精細的結果。Fig-06是作者在論文中給出的融合組合。第一列的FCN-32是指將conv7層直接放大32倍的網路;而FCN-16則是將conv7層放大兩倍之後,和pool4做結合再放大16倍的網路,以此類推。這些網路對應到的成果圖就是上面的Fig-05。可以發現,考慮越多不同尺度的feature map所得到的最終prediction map之精細度也越高,越接近ground-truth。
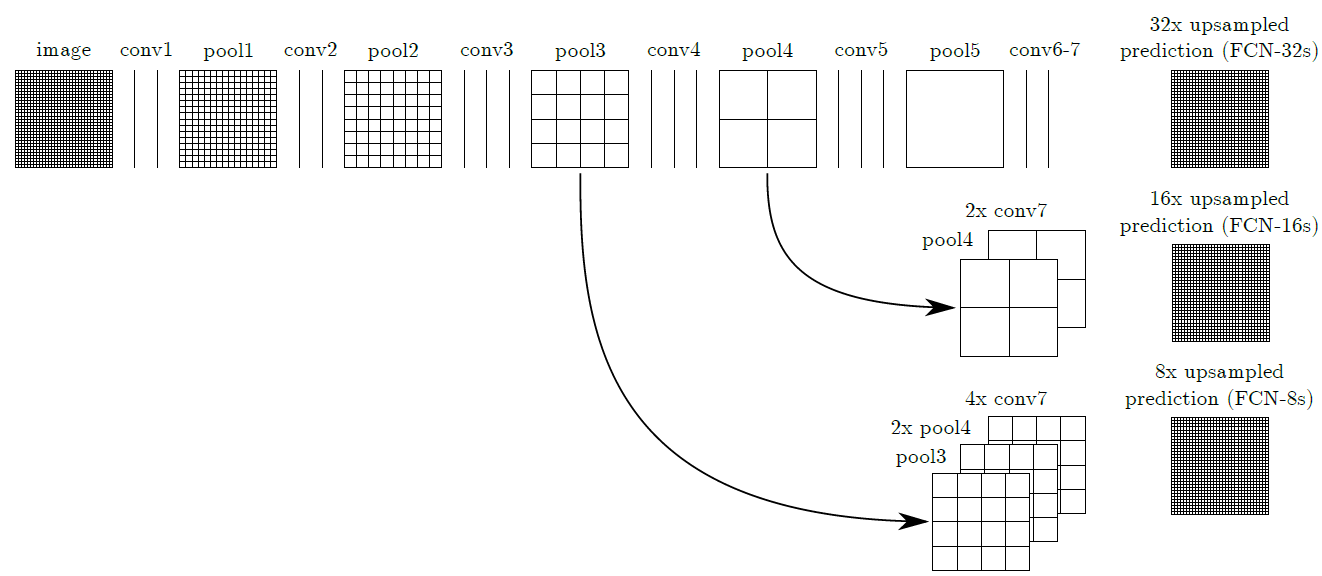
Fig-06
Semantic Segmentation
這個prediction map裏頭究竟是什麼呢?我們看下面Fig-07這張圖,若它經過了FCN的處裡得到的prediction map,就如同右邊那張以數字和顏色對應類別的圖。
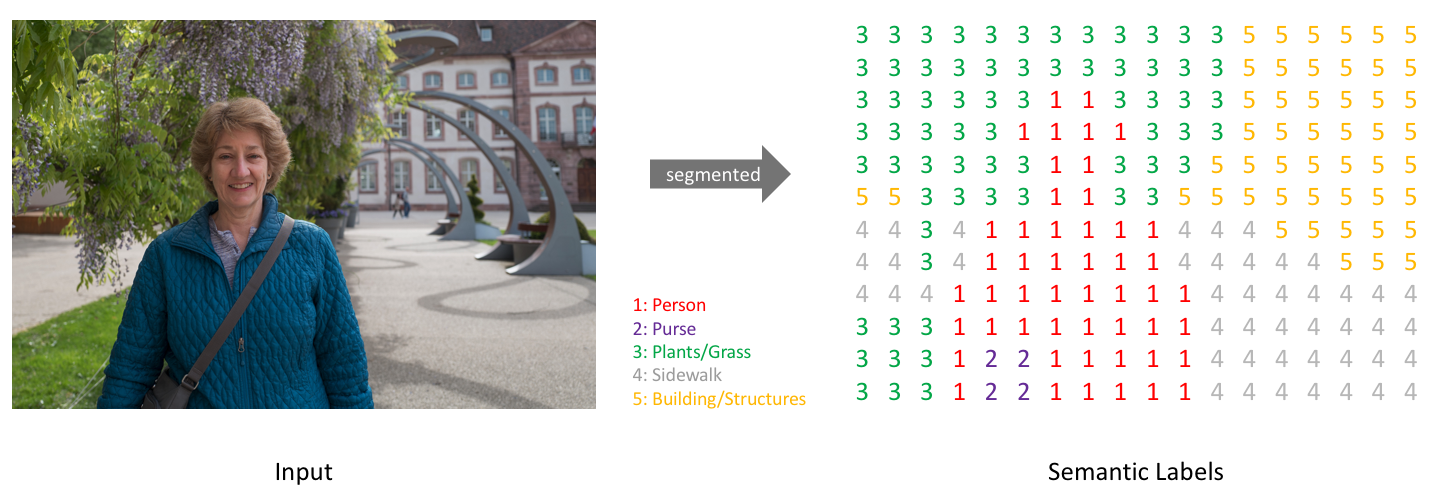 Fig-07. Quoted from here.
Fig-07. Quoted from here.
那我們把每一個channel都拆開來看,就會發現。FCN計算各個像素的類別分類的softmax機率後,會取channel-wise的最大機率,將最大機率所在的channel作為該位置像素所屬的類別,而以該類別的顏色呈現。這就是影像的semantic segmentation在做的事情。
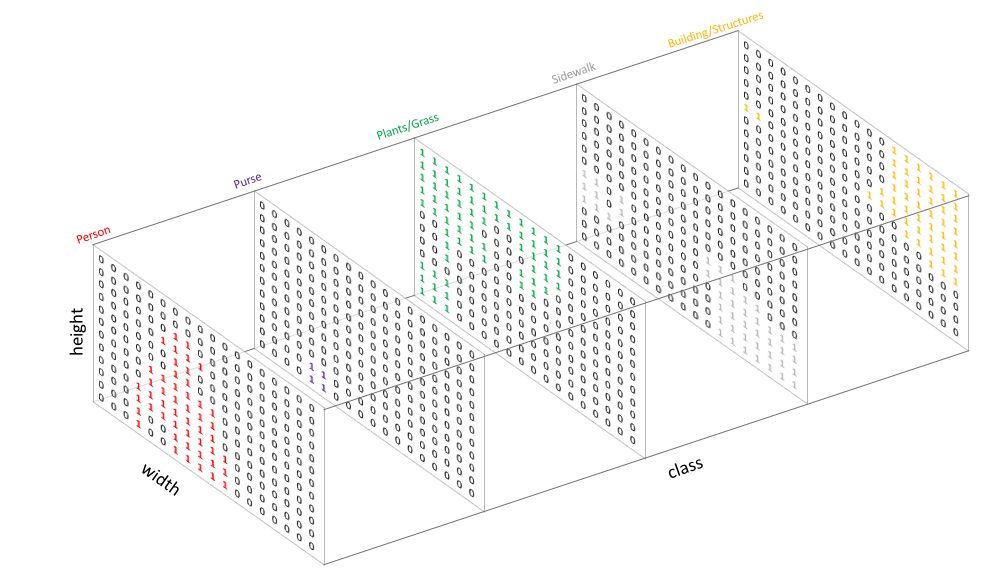
Fig-08
結語:
到這邊我們大致上了解了object detection的歷來的幾個發展方向,也知道影像中的semantic segmentation目前的主流方法FCN是如何進行的。當然它的缺點就是無法將同一類別的個體分割,這在實際應用上就造成了不小的麻煩,也因此有人認為這是一個不好的方向。但它終究是為Instance segmentation的發展有重要的貢獻。
這是我個人對這篇論文的消化,如果有錯誤之處,請各位朋友指教或幫我指出
如果喜歡這篇文章,記得在下面幫我按個Recommend↓
謝謝~
留言