
[物件偵測] S9: Mask R-CNN 簡介
前言
物件辨識發展到現在,透過我們前面所介紹的這些方法,總算是產生了一個集大成的模型-Mask R-CNN。他集結了Faster R-CNN的two-stage模型,再加上FPN的方法利用不同維度下特徵層級高的feature maps來進行預測,也改良Faster R-CNN中ROI Pooling的缺點,使其邊界框和物體定位的經度可以真正達到像素等級,將準確率提昇10~50%之間。對於物體定位精度的提升,讓含括FCN的概念的Mask R-CNN,可以對物體實現效果非常好的instance segmentation。
論文: Mask R-CNN
演算法架構
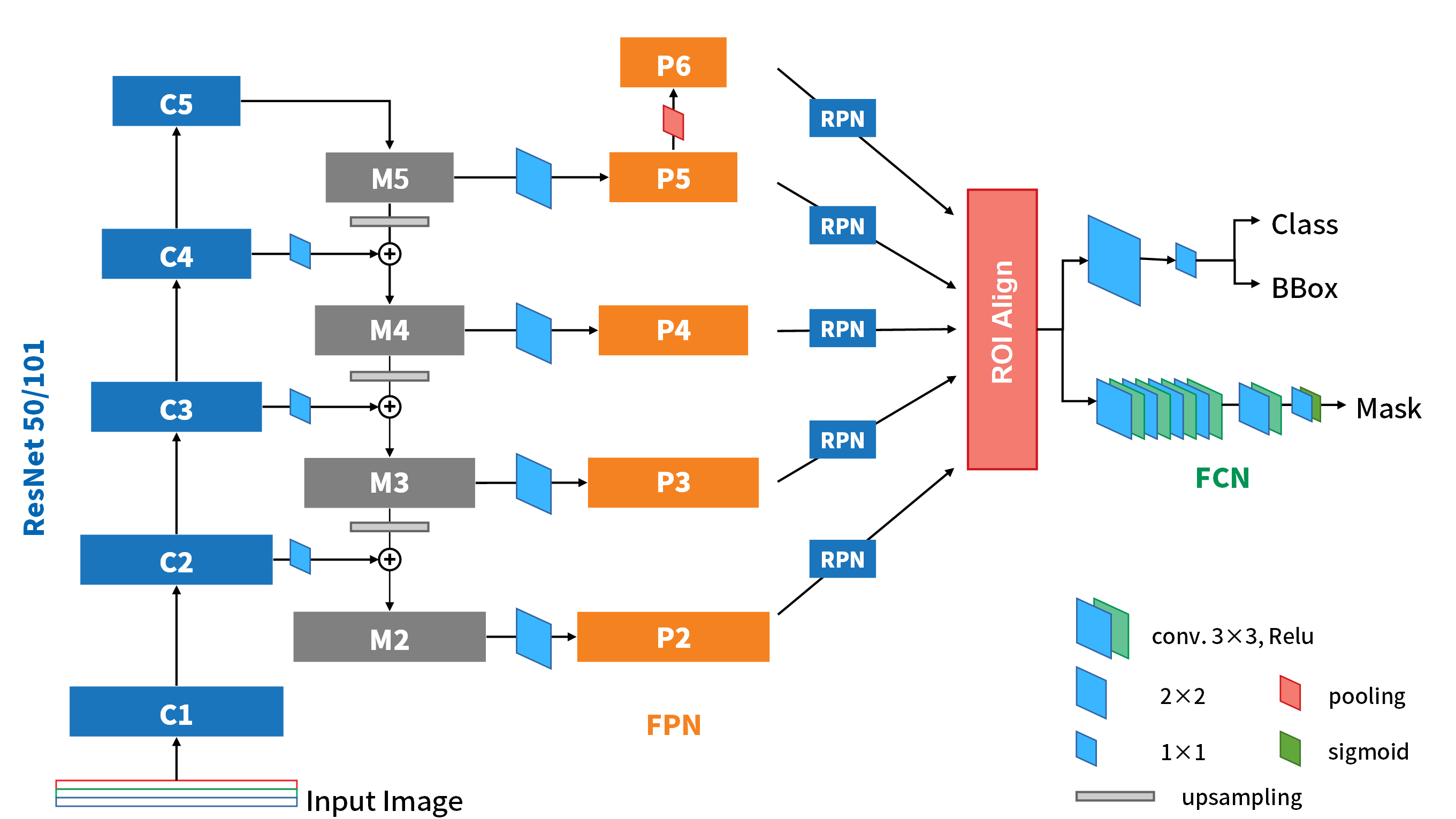 Fig-01
Fig-01
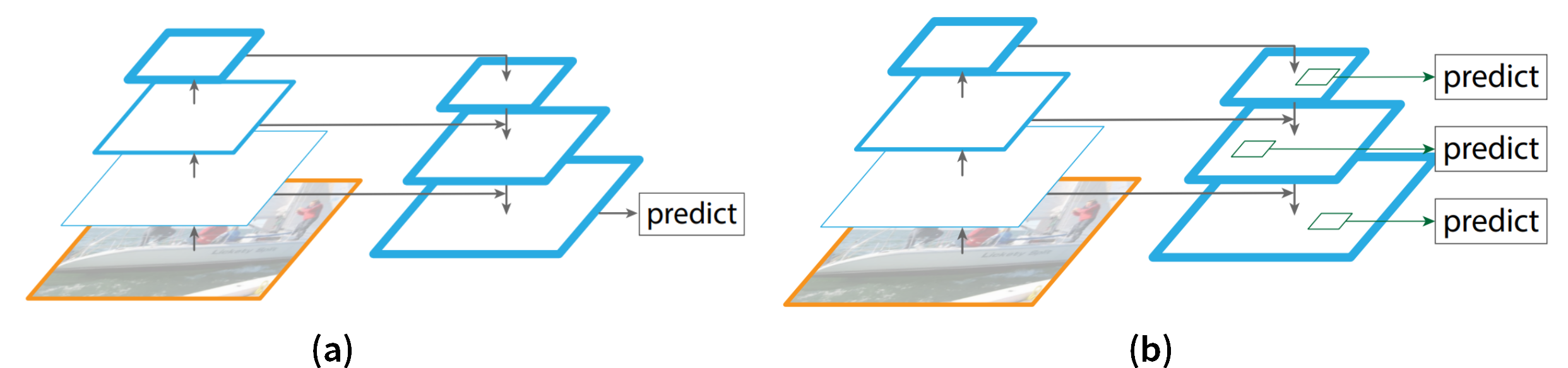
Mask R-CNN的詳細架構圖如Fig-01。基本上我們可以看到基本上他就是Faster R-CNN的進化版,再加上一個分支來處理instance segmentation(也就是Mask)。這裡頭很多熟悉的地方像是之前有介紹過的FPN、RPN、FCN,還有一個從ROI Pooling演變而來的ROI Align。因為上述這些NN,基本上都與之前介紹過的很相似,所以以下我們就針對Mask R-CNN的改變,以及它在檢測上的新分支來做說明。
FPN
在FPN的部份,由ResNet(or ResNeXt)50/101的C2~C5 block可以獲得P5~P2的feature map,不過記得FPN原文中,還在P5上再pooling一次,得到更小(粗糙)的feature map P6,來對實際影像中更大的物體提出proposal。而P6因為只是拿來提出proposals的,實際上在切feature map時,不會在P6上切(FPN paper Eq-1),所以P2~P6會進RPN,而P2~P5才會進後面的detector部份。
ROI Align
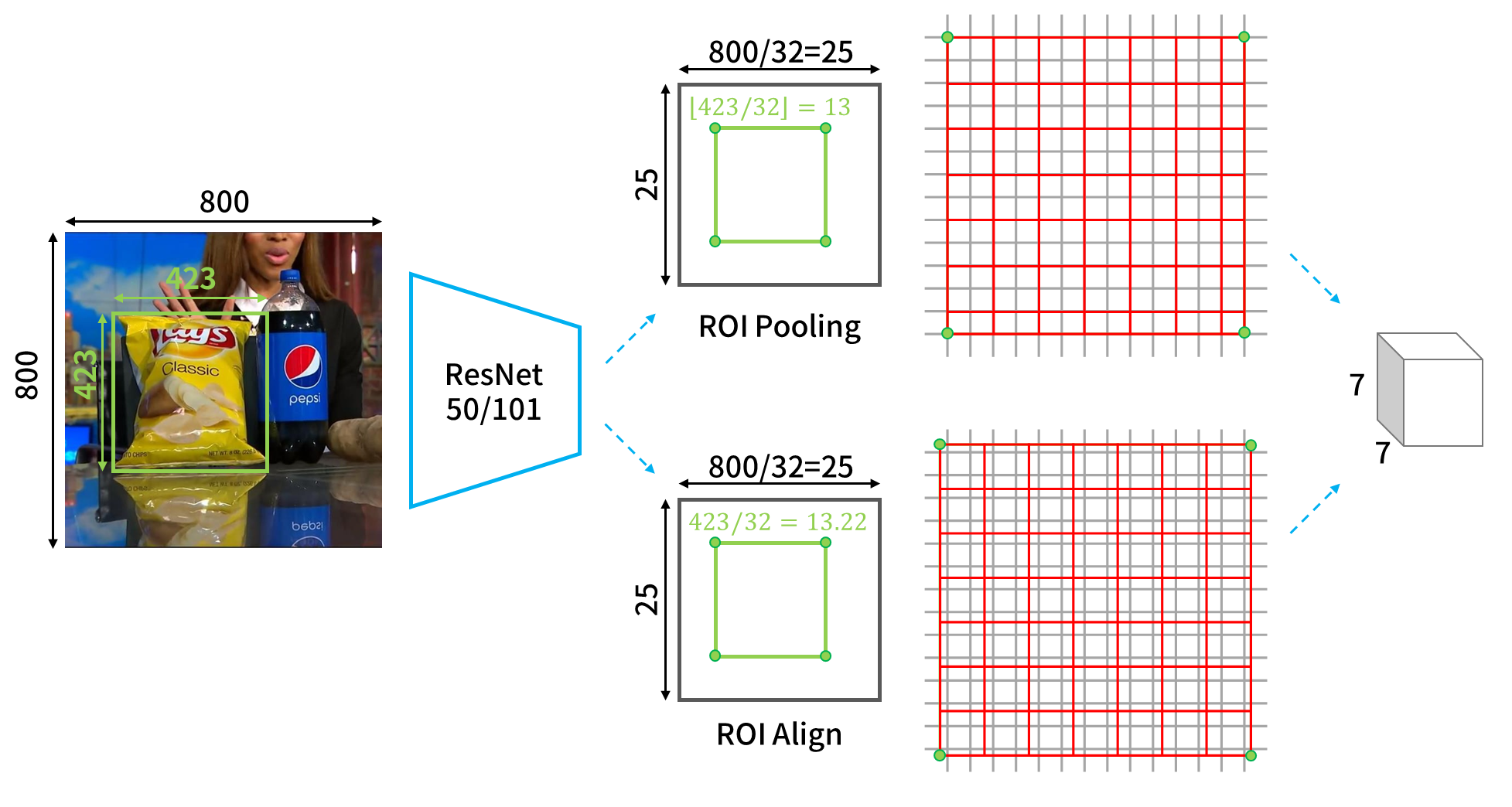 Fig-02
Fig-02
ROI Align最重要的改良點就是對於位置的描述。若我們以綠色框與角點代表物體的邊界框和位置,則可以看到在之前的ROI Pooling中,總共需要經過兩次的取整。第一次是物件在原圖上要映射到feature map上時,邊界框的尺寸和位置的取整(如Fig-02中的上路),第二次是ROI準備要進入n×n的ROI pooling時,分割成n×n網格的取整(如Fig-02中的上路)。這兩次取整都會對預測出來的邊界框反推回原圖尺寸時,產生不小的偏差。因此如果直接在原有的架構上加上mask分支,就會發現mask和物體錯位的情況很嚴重。 ROI Align就只是使用比較優雅的方式,不直接取整,就能獲得很好的進步。可以看到以邊界框和位置的部分來說,我們可以看到在Fig-02的下路中,綠色點是沒有恰落在灰色網格上的。而要做pooling的時候,也是採整個ROI均分成n×n網格(以下稱bins)的方式進行pooling。不過因為如此,就會在每個bin中都含括到若干個feature map上的像素,所以作者採用雙線性內差的方式來進行插值才做pooling。詳細地說,以Fig-03為例,在feature map上,會取當前ROI中的某個bin中的鄰近4點,做雙線性內插,之後在對每個bin中的4個’‘。’‘進行pooling的動作,來提出ROI。值得一提的是,作者試驗出以4點做內插效果最好,但是只有1個點的表現也幾乎有一樣的水準。這顯示對於定位結果的好壞,內插考量的點數並不是太重要的因素。重要的點還是在取整造成的影響,特別是今天對於辨識的物體若在影像中是小的,則些微的偏差都對物體定位的誤差造成很大的誤差貢獻。
 Fig-03
Fig-03
Loss
Mask R-CNN的loss function是
\[L=L_{cls} + L_{box} + L_{mask}\] Eq-01
其中,\(L_{cls}\)和\(L_{box}\)的部份和Faster R-CNN是一樣的。至於在mask分支的部分,輸出是m×m×K,m是mask的解析度,K是class數量。以COCO資料集來說,K就是80個類別。在Mask R-CNN中,mask的分支雖然也是採用FCN的設計,但是其活化函數和損失函數卻並不是FCN常見的softmax和cross entropy的組合,而是採用sigmoid,和average binary cross entropy。並且,mask分支會對進來的ROI給出所有類別的mask(也就是K個mask),卻不是每個mask的損失都會計入\(L_{mask}\)中。而是根據分類分支所判斷的結果是k類,才計算mask分支上第k類的mask的loss,計入\(L_{mask}\)中。
Instance Segmentation
那為何Mask R-CNN可以做到很好的instance segmentation,而不是像一般採用FCN方法的模型,只能產生semantic segmentation或是有明顯瑕疵的instance segmentation呢?第一點是因為Mask R-CNN是平行判斷類別和mask的,分支網路是獨立被訓練出各自的參數,而且是一次一個ROI來根據其類別判定的結果,選擇要使用的mask,所以個體之間因為是不同的ROI所以可以很容易就獨立,mask也可以獨立。但是FCN的方法中,判斷類別和mask是一起來的,這樣的機制會使得不同類別和mask之間的競爭,也因為一個類別一個mask的設計,無法獨立個體。另一個作者說是很重要的因素是,Mask R-CNN 的激活函數和損失函數是採用sigmoid與average binary cross entropy,如我們在前一節講到的。這樣的設計在作者的實驗中發現可以避免原本作法會產生的mask跨類別競爭的不利影響,而可以為mask的結果帶來很好的instance segmentation的結果,也就不會出現FCIS對於重疊物件會畫出奇怪的疊影物件這樣的系統誤差(如Fig-04)。
 Fig-04
Fig-04
結論
講到這裡,算是把Mask R-CNN的重點都解釋過了。我們也可以發現,它其實就是利用ResNet/ResNeXt 搭配FPN來強化特徵提取能力與特徵整合力的Faster R-CNN,並且將ROI Pooling 換成不會取整而影響精度的ROI Align,再多出一條mask分支來進行instance segmentation任務的網路。一言以蔽之,就是個集大成的網路。不過Mask R-CNN可是個相當龐大的模型,這也使得它的辨識速度並不夠快(單顆GPU達5 FPS),若是目標類別數量很多,訓練起來也非常耗時,這使得它在應用上並不實際。但是它絕對是一代經典的網路。若沒有先了解過Fast/Faster R-CNN的人,直接看它的論文可能會不知所云;但是如果是有先了解過的人,再來看這篇論文,相信會覺得十分滿足! 如果喜歡這篇文章,記得在下面幫我按Recommand ↓ 謝謝~

留言