
[物件偵測] S10: YOLO v3 簡介
前言
這總算是近期的最後一篇物件偵測論文的介紹文。作者寫這篇論文的時候就提到,他當時沒有繼續花太多心力在改進YOLO系列的演算法上。這次只是稍稍加了一點東西進來,產生YOLO系列的第三代,所以就以比較輕鬆的「技術報告」來呈現他所引入和嘗試的方法。這些改進主要圍繞在邊界框預測、分類預測、backbone網路的改良。
論文:
YOLOv3: An incremental improvement
YOLOv3: An Incremental Improvement
演算法架構
邊界框預測
YOLOv3在邊界框的預測上,改成以logistic regression來預測邊界框包含物體的分數。不過這裡的評分目標訂定方式和Faster R-CNN中的方式有一點不同,YOLOv3只把與ground-truth重疊率最高的那個邊界框認作滿分1,不是被認作最好的那些邊界框,就不會對分類或是邊界框座標的損失有做貢獻。
分類預測
這裡作者指出,以softmax作為分類預測器的函數其實對於分類的進步沒有幫助。因為softmax是基於假設每個類別之間是獨立關係,但是當你處理的分類問題中,不同類別但他們其實是相似東西的這種情況時,softmax的假設就不成立了。因此,YOLOv3改用independent logistic classifiers,並搭配binary cross-entropy來衡量分類上的損失。
Backbone網路
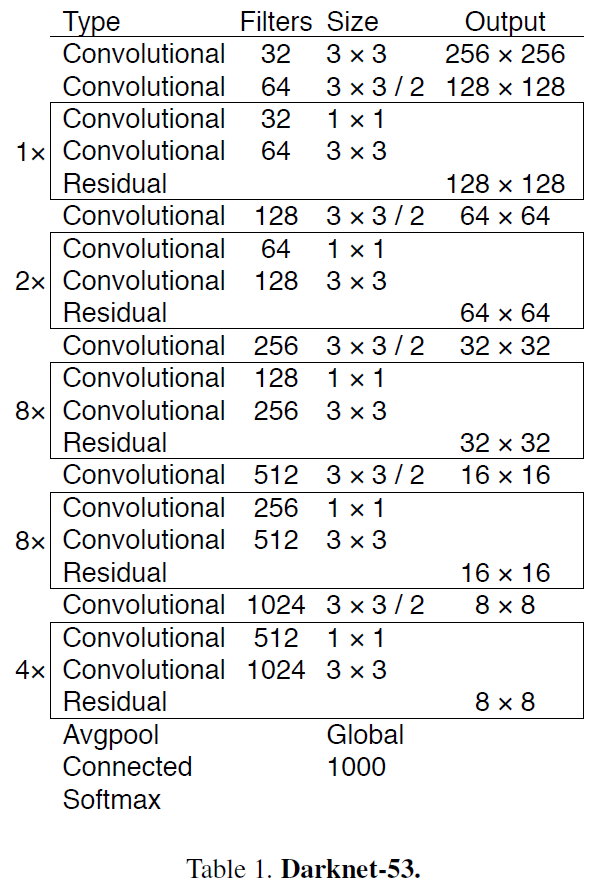
YOLOv3最大的亮點就是作者又發展出一個全新的Darknet網路來做為YOLOv3的特徵提取Backbone,名為Darknet-53。Darknet-53作為單純的CNN的話,架構在論文裡面已經有很清楚的表格展列了,而他的表現在top-5的正確率可以說是比darknet-19提升了2的百分點,甚至與超過100層的ResNet有著相同等級的表現,速度的表現也可以保持在78 FPS。
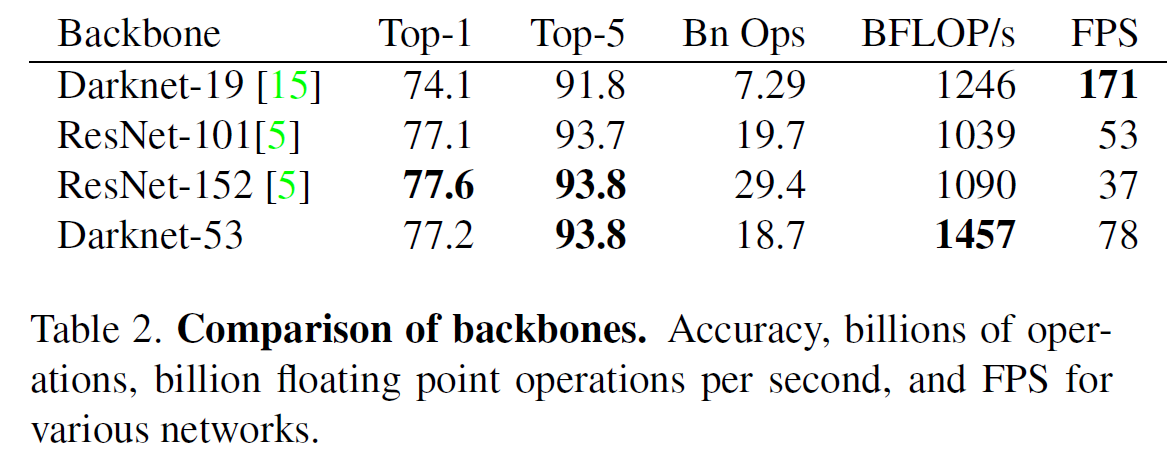
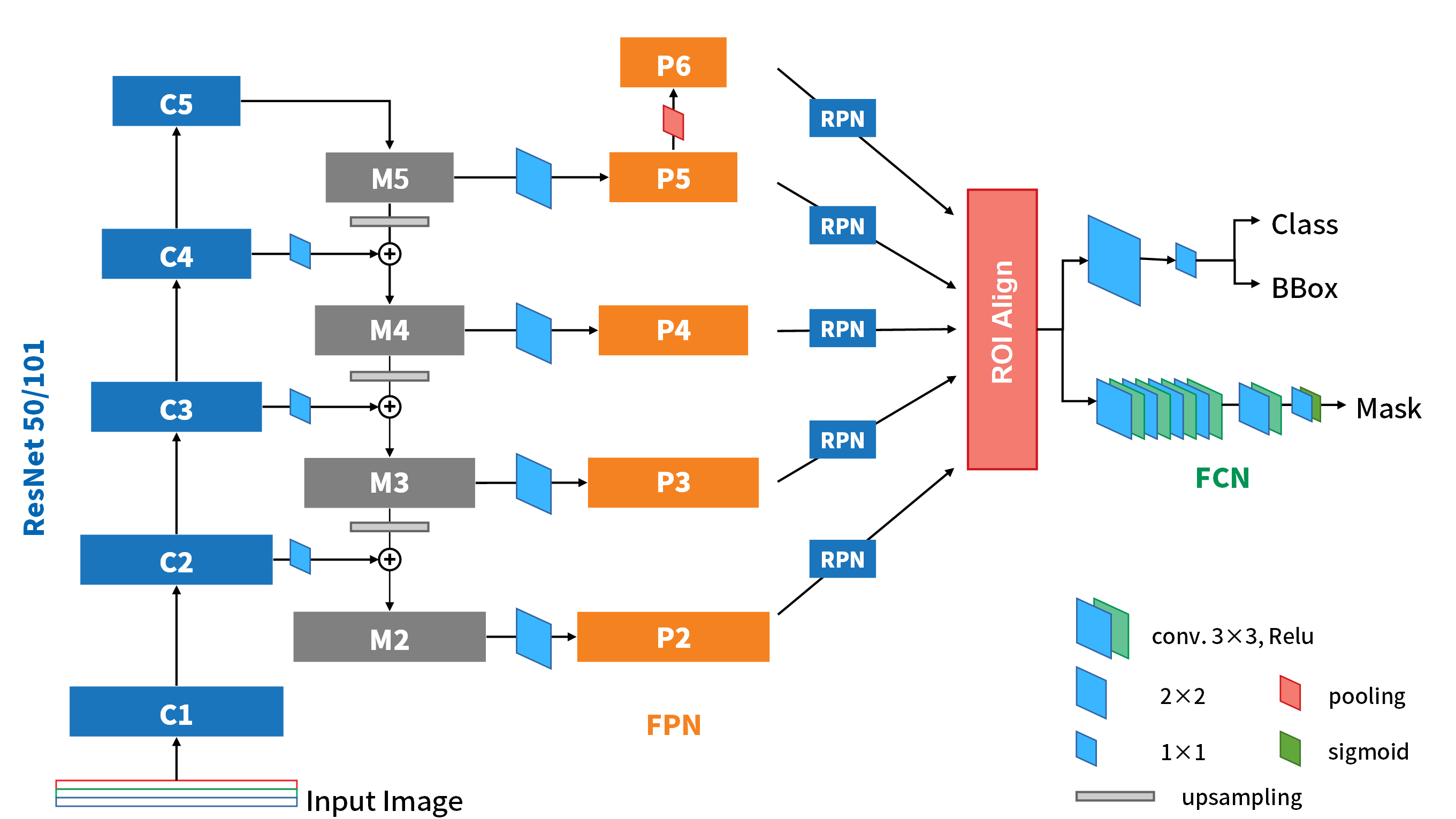
而應用到YOLOv3時,darknet-53結合了FPN的手法,來在YOLOv3中實現3種不同尺度下的偵測。和FPN比較明顯不同的是,在YOLOv3中,不同尺度的feature map要建構關係時,並不是element-wise的相加,而是直接將兩個map相接。綜上所述,YOLOv3的架構如下圖所示。作為尺度最大的scale 1,負責辨識影像中較細小的物體,而尺度最小的scale 3,則辨識影像中較大的物體。
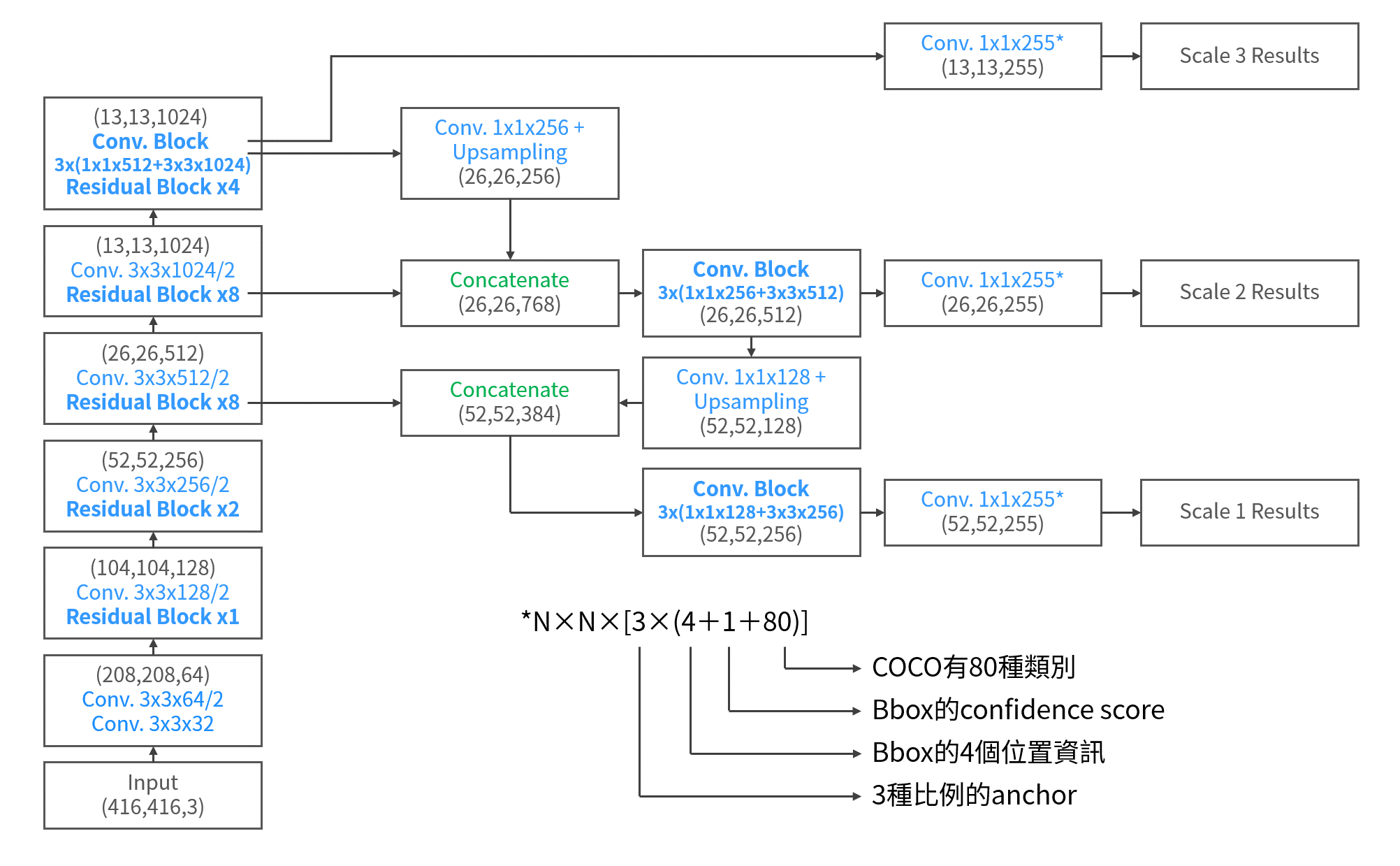
結論
這張表說明了YOLOv3和不同的物件偵測模型的表現。我們可以看到因為加入了FPN的概念,所以和YOLOv2相比確實有了很大的長進,和two-stage的模型相比也已經可說是有相同程度的辨識率。但是和RetinaNet的表現相比,精確度似乎還存在著一段落差。不過在辨識速度上,RetinaNet可是需要比YOLOv3多3倍的時間。因此YOLOv3的重要性在於,在保留one-stage模型的特性底下,提供了一個辨識率和速度兩種要求都有高水準表現的一個解決方案。最近要登入國軍online了,所以之後找時間再來分享RetinaNet的內容吧!

留言